Gated RNN
RNN 的问题
因为 BPTT 会发生梯度消失和梯度爆炸的问题,所以不擅长学习时序数据的长期依赖关系。
梯度消失和梯度爆炸
RNN 层通过向过去传递“有意义的梯度”,能够学习时间方向上的依赖关系。此时梯度(理论上)包含了那些应该学到的有意义的信息,通过将这些信息向过去传递,RNN 层学习长期的依赖关系。但是,如果这个梯度在中途变弱,则权重参数将不会被更新。
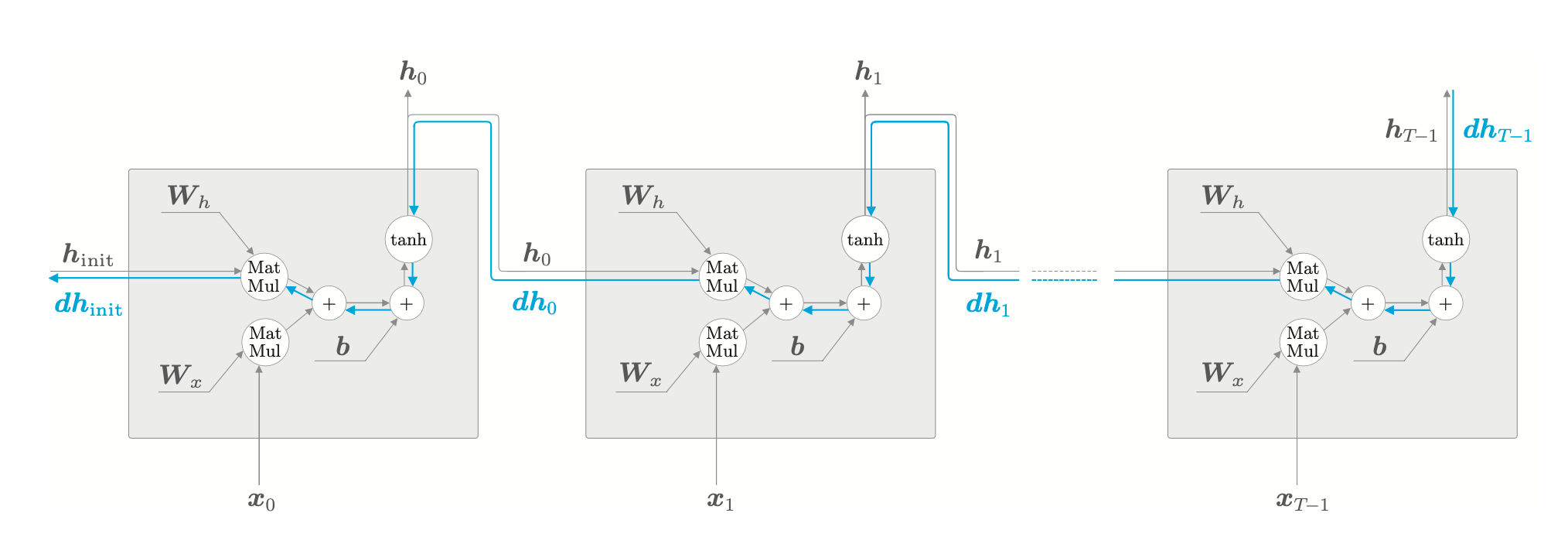
RNN 层在时间方向上的梯度传播
在反向传播中,梯度主要经过 tanh 以及矩阵乘法两个函数。梯度消失和梯度爆炸正是由于这两个函数的特点导致的。
梯度爆炸的对策
解决梯度爆炸一般采用梯度裁剪(gradients clipping)的办法。
\[ \text{if} \ ||\hat{\textbf{g}}|| \ge \text{threshold:} \\ \ \ \ \ \hat{\textbf{g}} = \frac{\text{threshold}}{||\hat{\textbf{g}}||} \hat{\textbf{g}} \]
假设可以将神经网络用到的所有参数的梯度整合成一个,并用符号\(\hat{\textbf{g}}\)表示。如果梯度的 L2 范数\(||\hat{\textbf{g}}||\)大于或者等于阈值,就按上面的方式修正梯度。
def clip_grads(grads, max_norm): |
梯度消失和 LSTM
下面是 LSTM 与 RNN 的接口比较图。
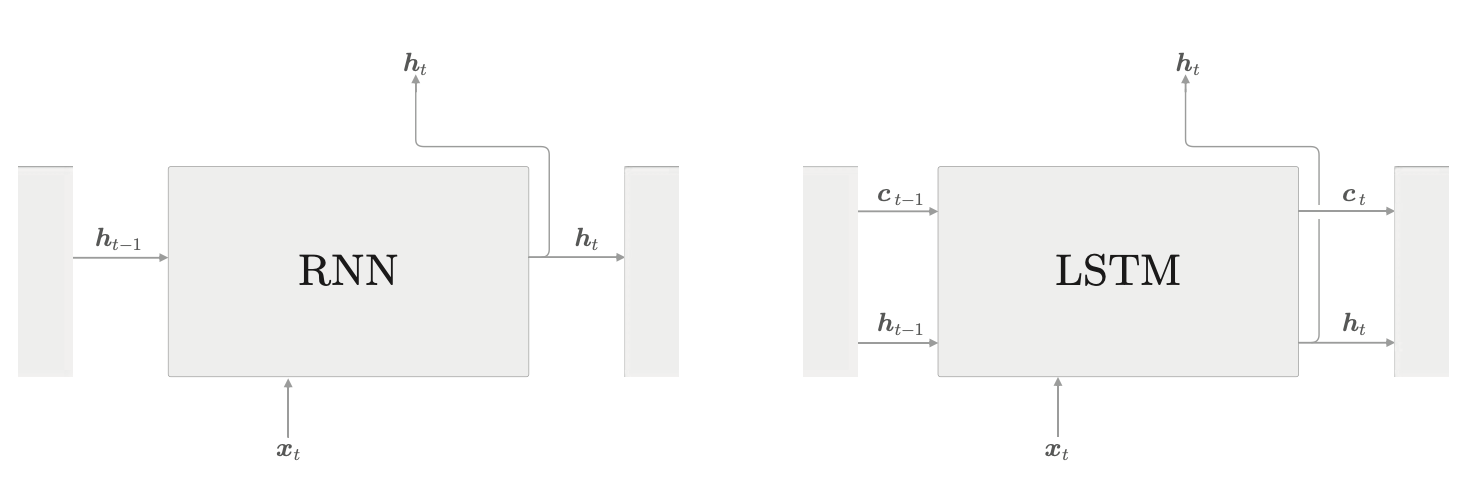
LSTM 增加了路径 \(c\)。这个 \(c\) 称为记忆单元,它只在 LSTM 内部发挥作用,并不向外层输出。
LSTM 的结构
输出门
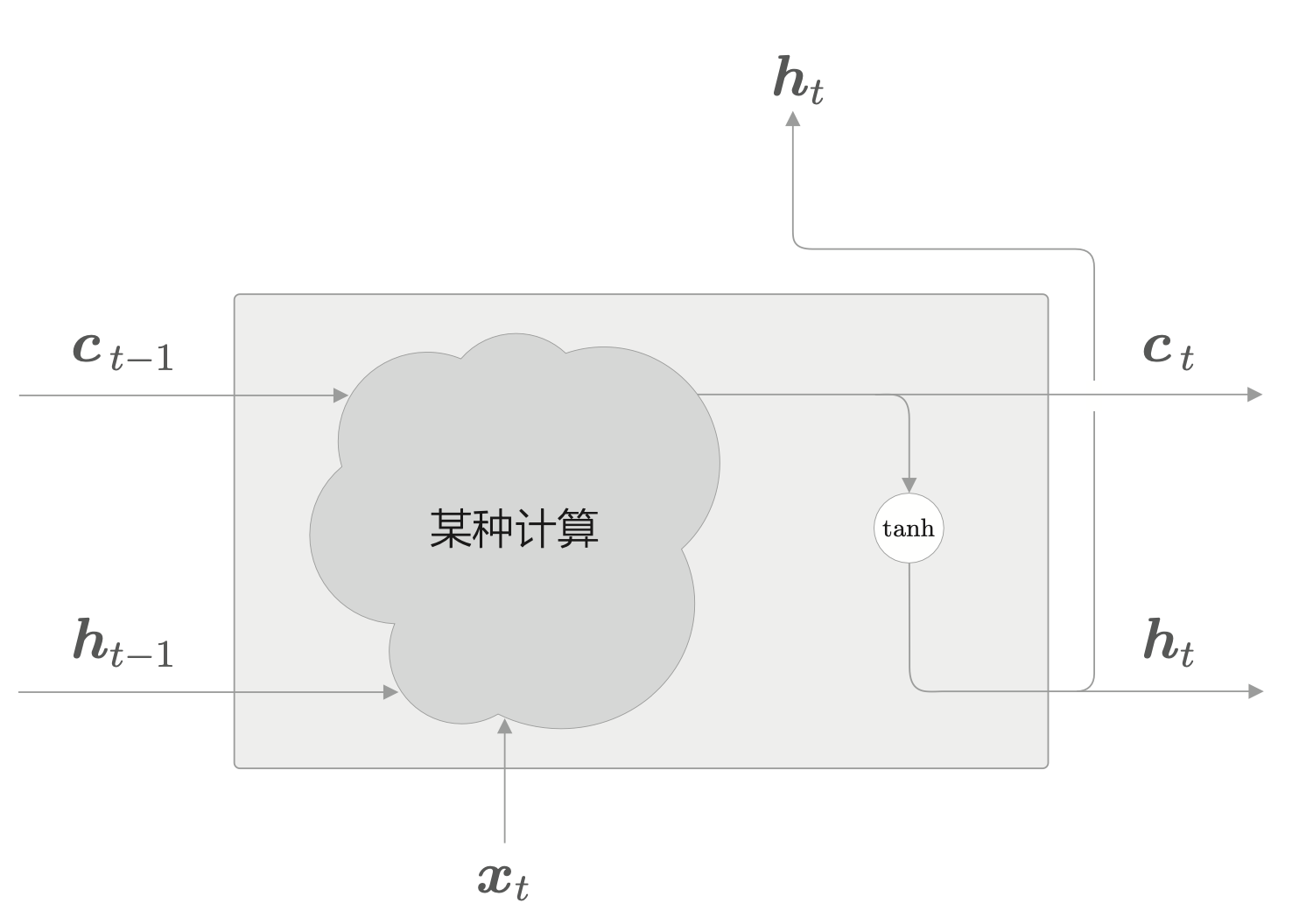
LSTM 有记忆单元 \(c_t\)。这个 \(c_t\) 存储了时刻 \(t\) 时的 LSTM 的记忆。然后,基于这个充满必要信息的记忆,向外部的层(和下一时刻的 LSTM)输出隐藏状态 \(h_t\)。
如右图所示,当前的记忆单元 \(c_t\) 是基于三个输入 \(c_{t-1}, h_{t-1}, x_t\) 经过某种计算计算出来的。这里的重点是 \(h_t = \tanh(c_t)\)。
下面考虑对 \(\tanh(c_t)\) 施加门。这作用在于针对 \(\tanh(c_t)\) 的各个元素,调整它们作为下一时刻的隐藏状态的重要程度。由于这个门管理下一个隐藏状态 \(h_t\) 的输出,所以称为输出门(output gate)。
输出门的开合程度(流出比例)根据输入 \(x_t\) 和上一个状态 \(h_{t-1}\) 求出。sigmoid 函数用 \(\sigma\) 表示。下面是输出门的输出计算方式。
\[ o = \sigma(x_t W_x^{(o)} + h_{t-1} W_h^{(o)} + b^{(o)}) \]
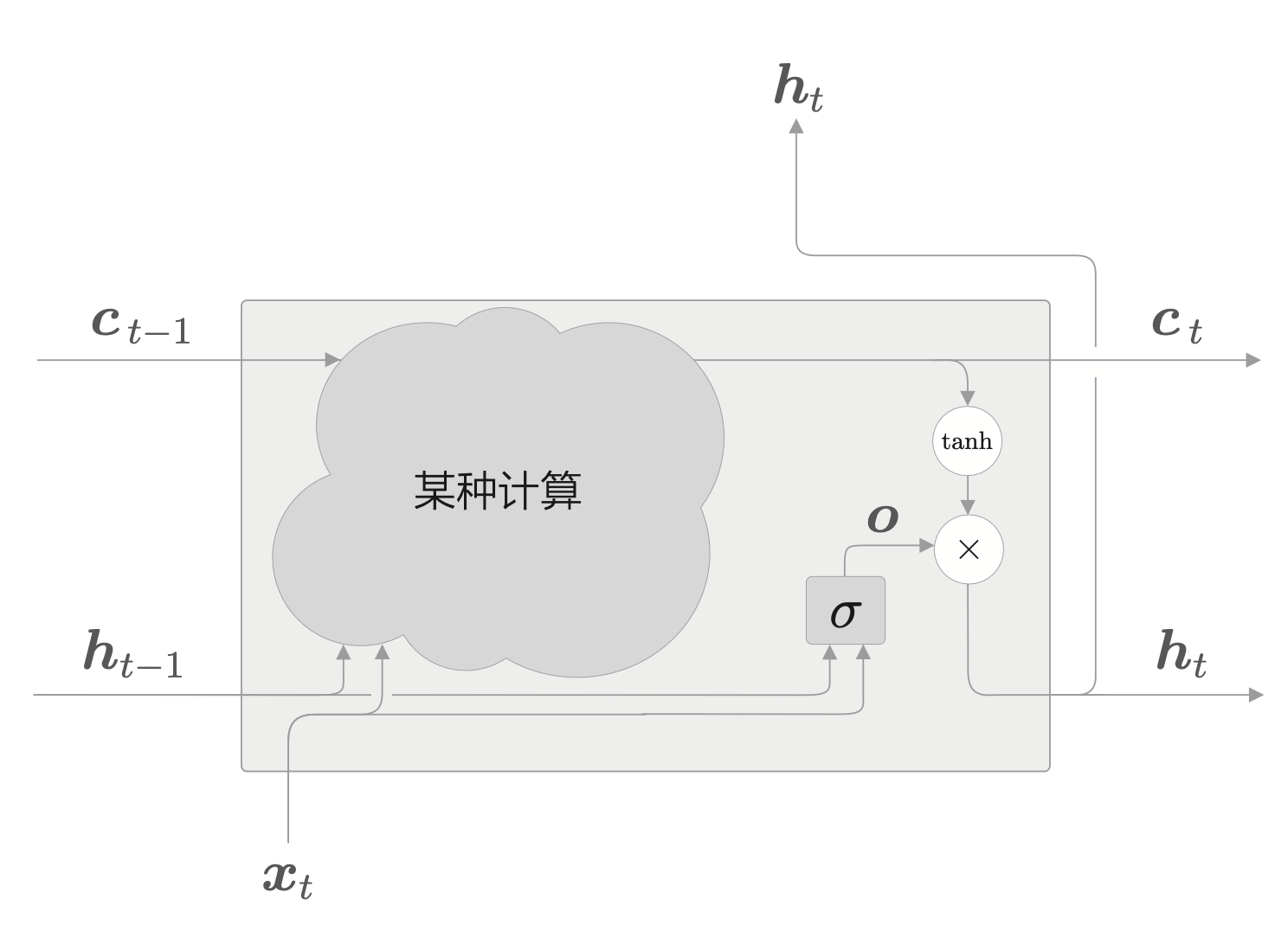
最后,得到输出 \(h_t = o \odot \tanh(c_t)\)。这里的乘积 \(\odot\) 是对应元素的乘积。
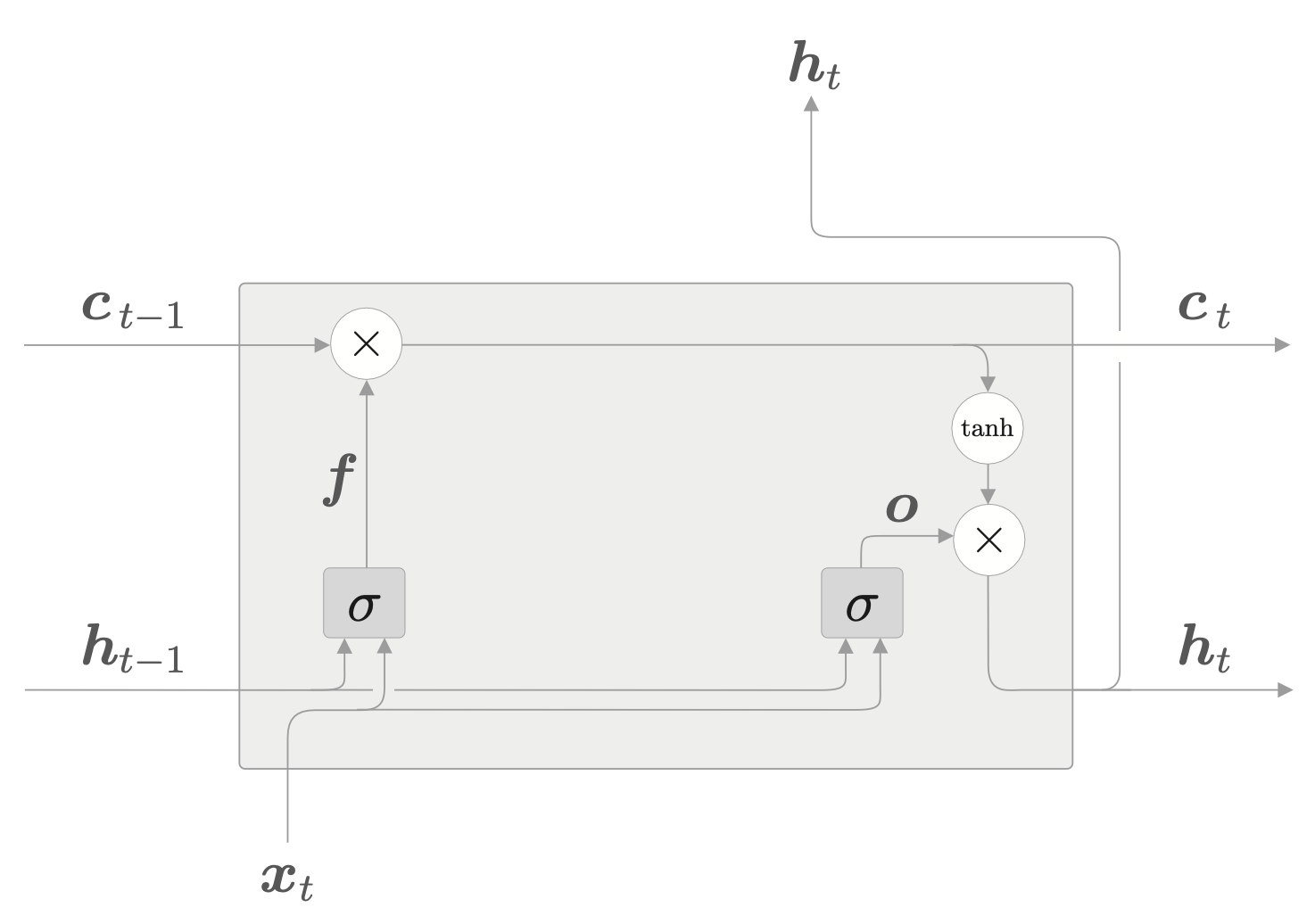
遗忘门
现在,我们在 \(c_{t-1}\) 上添加一个忘记不必要记忆的门,称为遗忘门(forget gate)。
遗忘门的计算方式与输出门的计算方式类似,最终也是算出一个权重,来决定 \(c_{t-1}\) 的重要程度。
\[ f = \sigma(x_t W_x^{(f)} + h_{t-1} W_h^{(f)} + b^{(f)}) \]
最后,得到输出 \(c_t = f \odot c_{t-1}\)。
新的记忆单元
遗忘门从上一时刻的记忆单元删除了应该忘记的东西,下面我们往这个记忆单元增加一些应当记住的新信息。
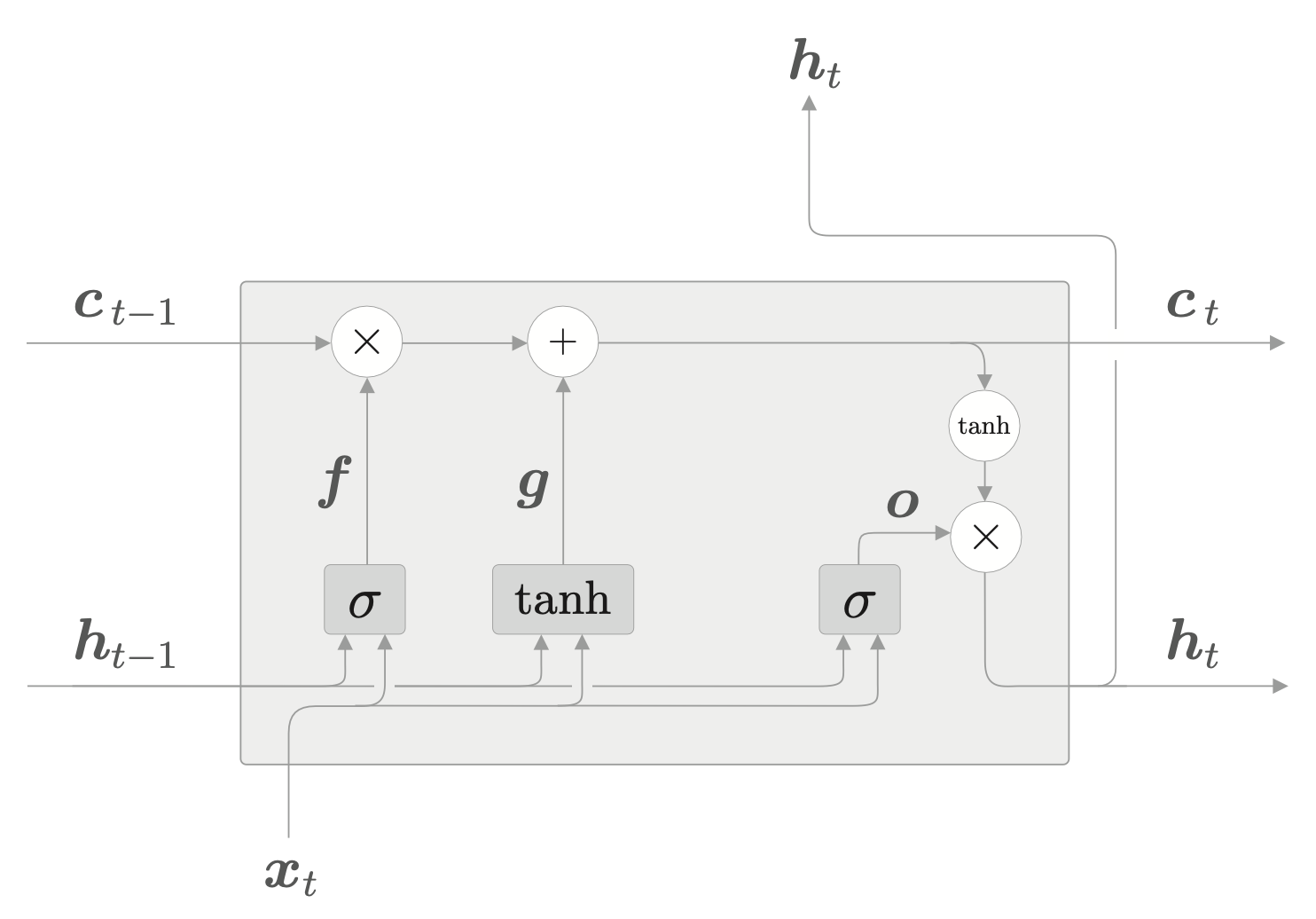
如上图所示,基于 \(\tanh\) 节点计算出的结果被加到上一时刻的记忆单元 \(c_{t-1}\) 上,这样一来,新的信息就被加到记忆单元中。这个节点的作用不是门,所以不用 sigmoid 函数。
\[ g = \tanh(x_t W_x^{(g)} + h_{t-1} W_h^{(g)} + b^{(g)}) \]
通过将这个 \(g\) 加到 \(c_{t-1}\) 上,从而形成新的记忆。
输入门
输入门用于控制新增信息的权重,是用来控制 \(g\) 的。
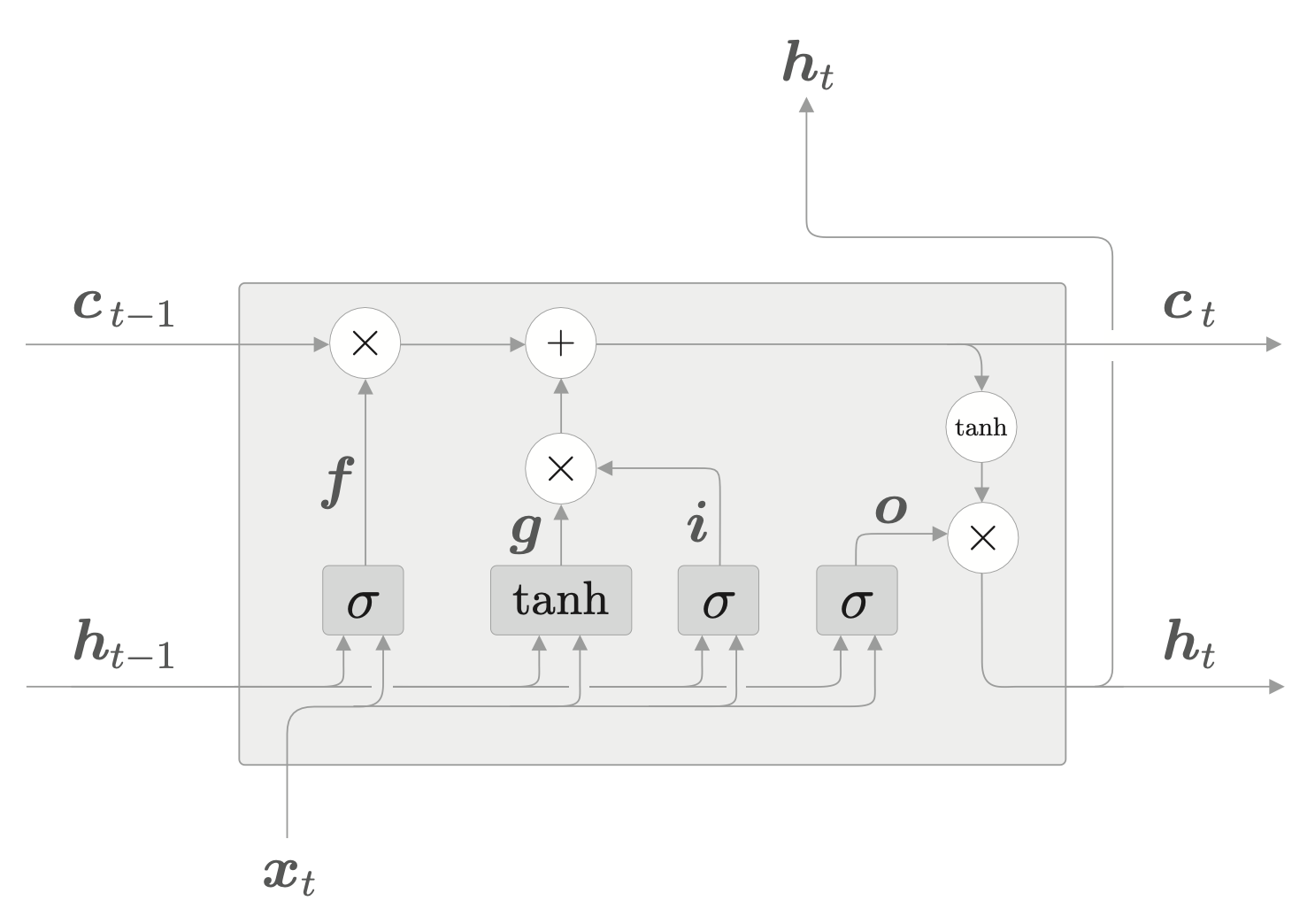
由于这是一个控制门,所以使用 \(\sigma\) 函数。
\[ i = \sigma(x_t W_x^{(i)} + h_{t-1} W_h^{(i)} + b^{(i)}) \]
由此,最终得到的 \(c_t,h_t\) 可以表示为
\[ \begin{align*} c_t &= f \odot c_{t-1} + i \odot g \\ h_t &= o \odot \tanh(c_t) \end{align*} \]
LSTM 的梯度流动
为什么 LSTM 不会引起梯度消失呢?可以通过观察记忆单元 \(c\) 来看出。
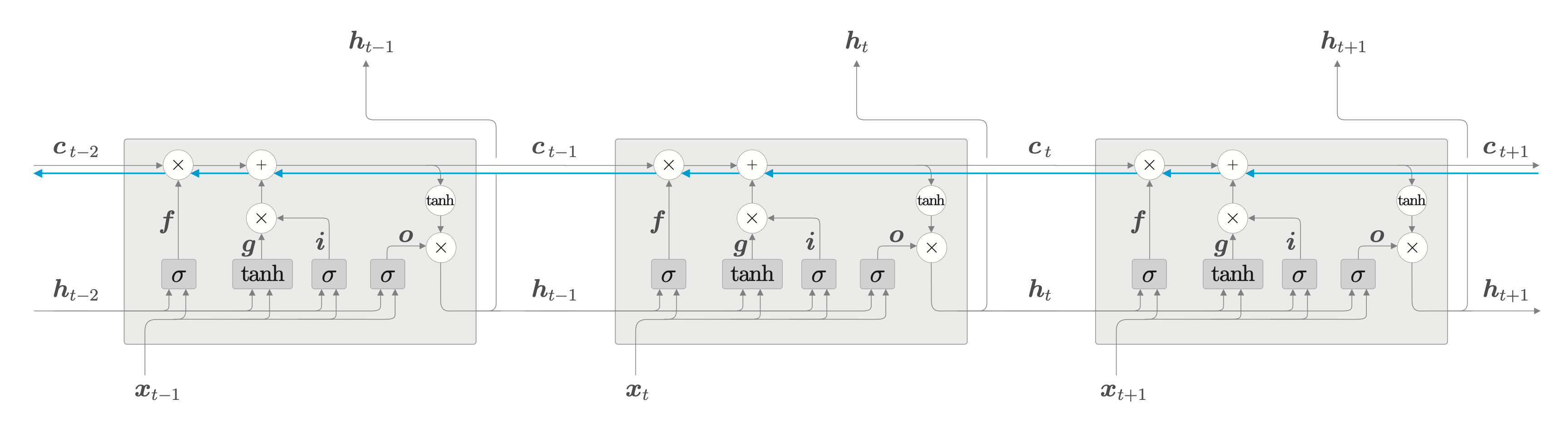
记忆单元的反向传播仅仅经过加法和乘法,加法会将梯度保持原状返回,而乘法节点并不是矩阵乘积,不会因为执行次数的叠加而产生梯度消失和梯度爆炸。
LSTM 的实现
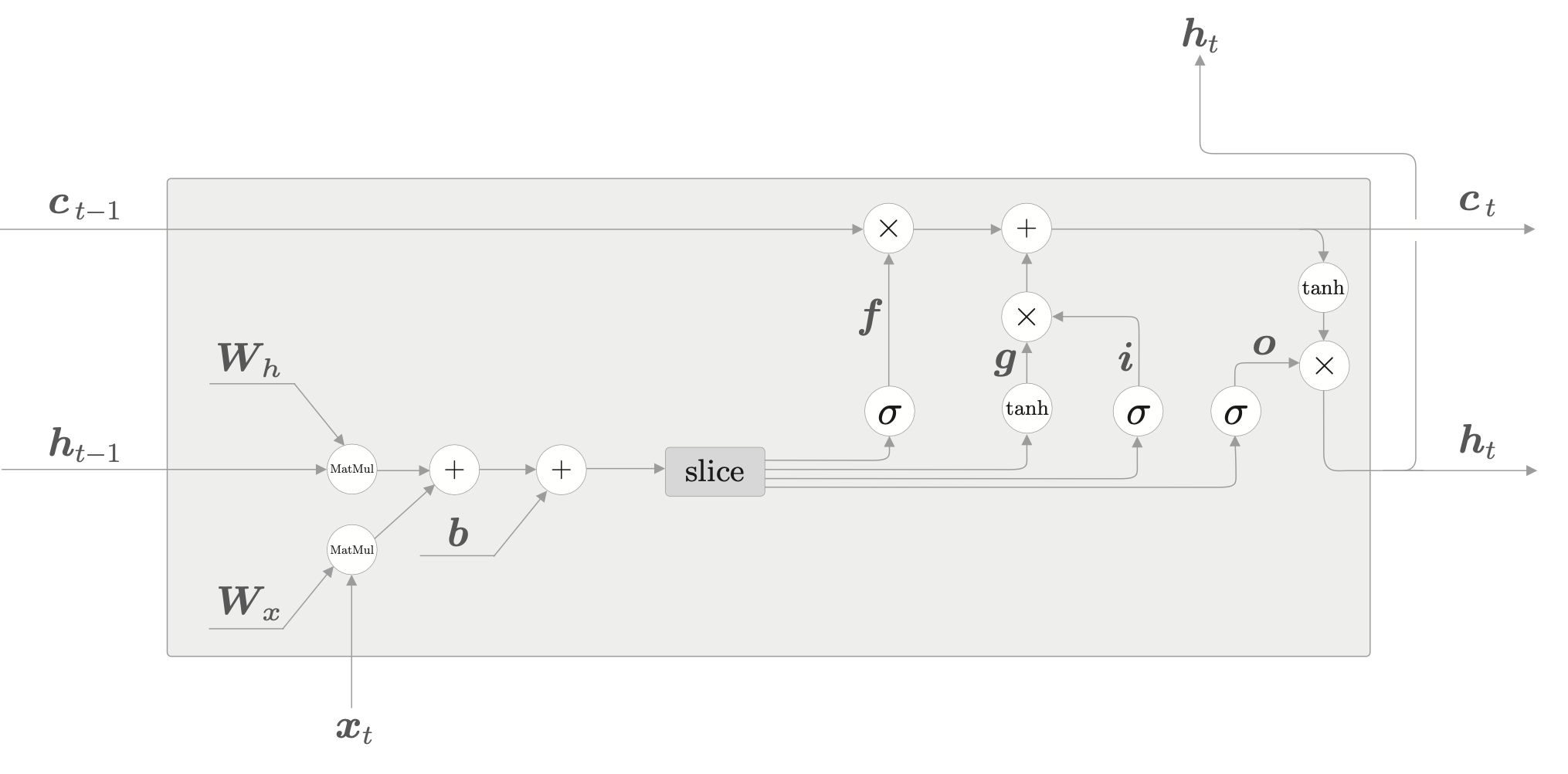
下面列出 LSTM 中涉及到的所有计算。
\[ \begin{align} f &= \sigma(x_t W_x^{(f)} + h_{t-1} W_h^{(f)} + b^{(f)}) \\ g &= \tanh(x_t W_x^{(g)} + h_{t-1} W_h^{(g)} + b^{(g)}) \\ i &= \sigma(x_t W_x^{(i)} + h_{t-1} W_h^{(i)} + b^{(i)}) \\ o &= \sigma(x_t W_x^{(o)} + h_{t-1} W_h^{(o)} + b^{(o)}) \\ c_t &= f \odot c_{t-1} + i \odot g \\ h_t &= o \odot \tanh(c_t) \end{align} \]
其中的式(1)~(4)可以合并为一个式子。
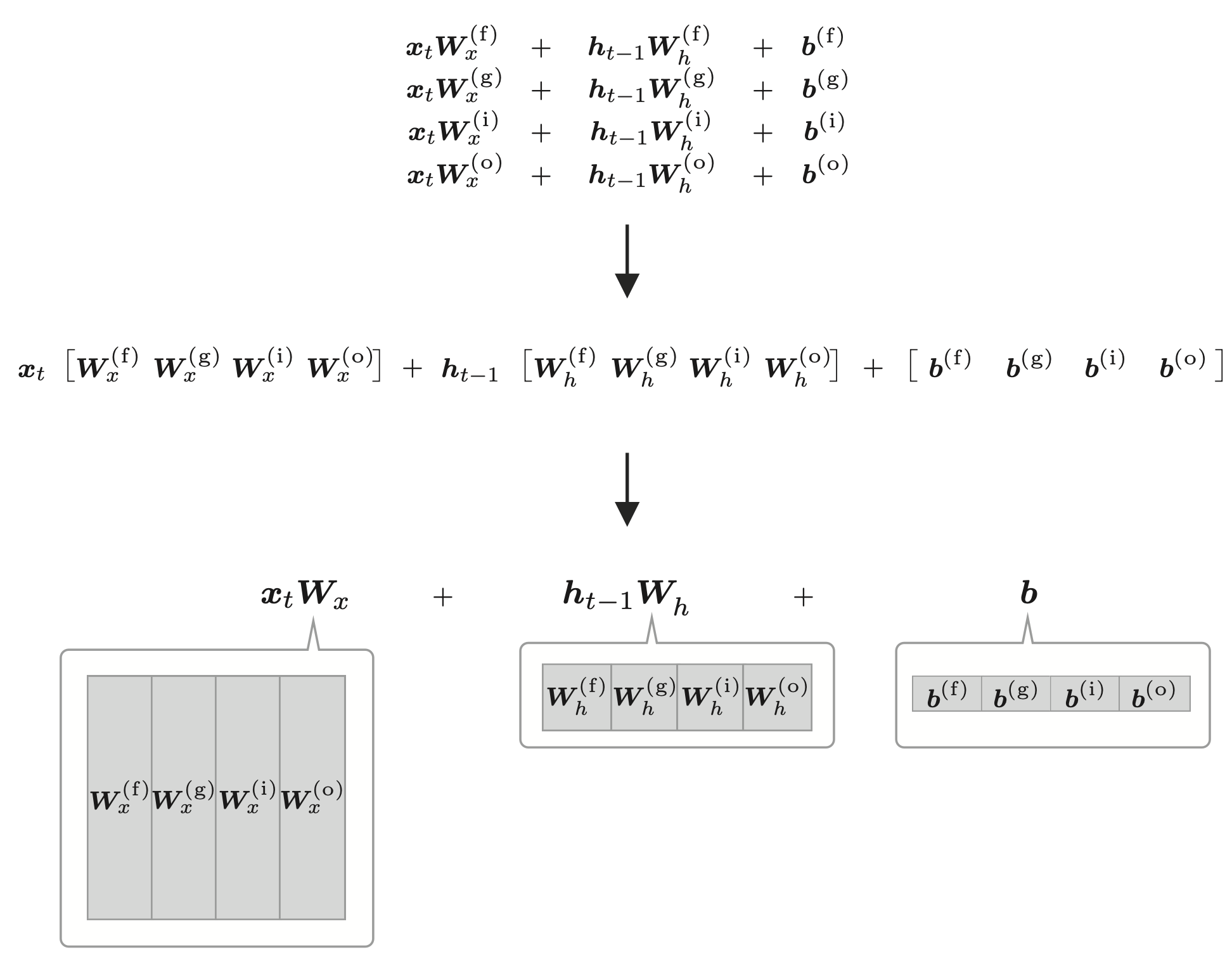
整合之后的计算图如下所示。
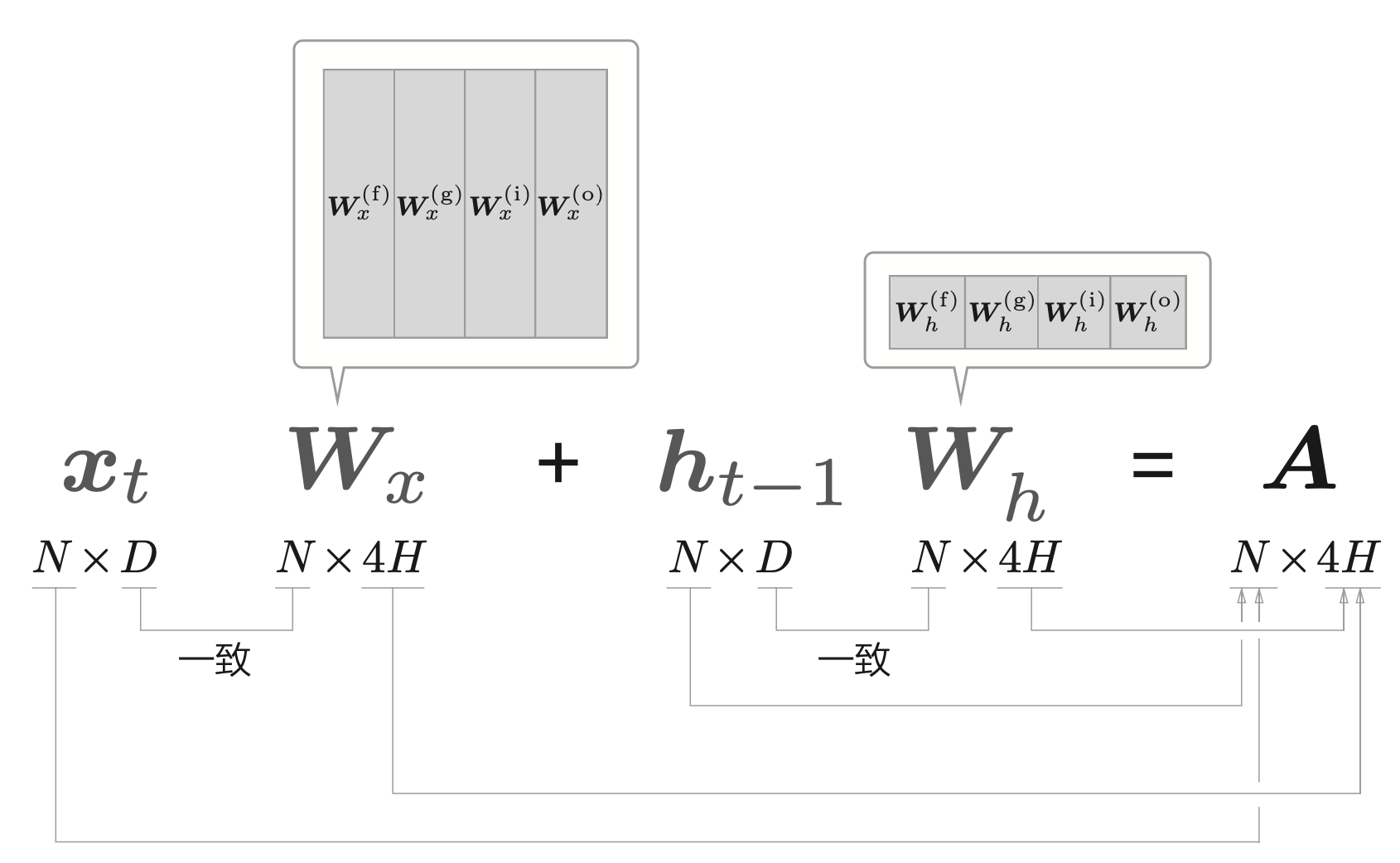
class LSTM: |