RNN
概率和语言模型
语言模型
语言模型(language model)给出了单词序列发生的概率。考虑由 \(m\) 个单词 \(w_1, \dots, w_m\) 构成的句子,将单词按 \(w_1, \dots, w_m\) 的顺序出现的概率记为 \(P(w_1, \dots, w_m)\)。使用后验概率可以将这个联合概率分解为
\[ p(w_1, \dots, w_m) = \prod^m_{t = 1} P(w_t | w_1, \dots, w_{t - 1}) \]
这个模型有时候也称为条件语言模型(conditional language model)。
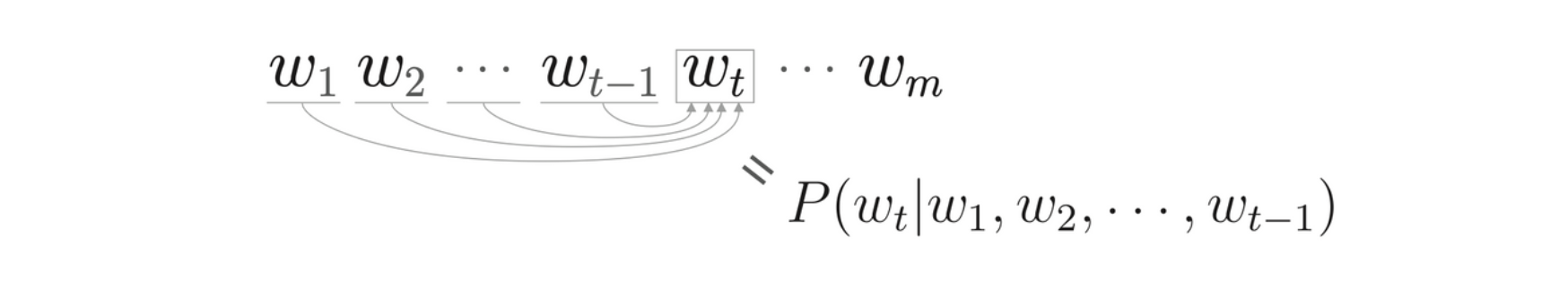
语言模型中的后验概率:若以第 t 个单词为目标词,则第 t 个单词左侧的全部单词 构成上下文(条件)
RNN
RNN(Recurrent Neural Network)为循环神经网络。与 CBOW 的最大区别在于,CBOW 会受到上下文大小的限制,如果窗口大小无法覆盖上下文,将无法进行正确的推理。但是通过 RNN 可以做到这点。
RNN 的循环结构
RNN 的特征就在于拥有一个环路,这个环路可以使数据不断循环。通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据。
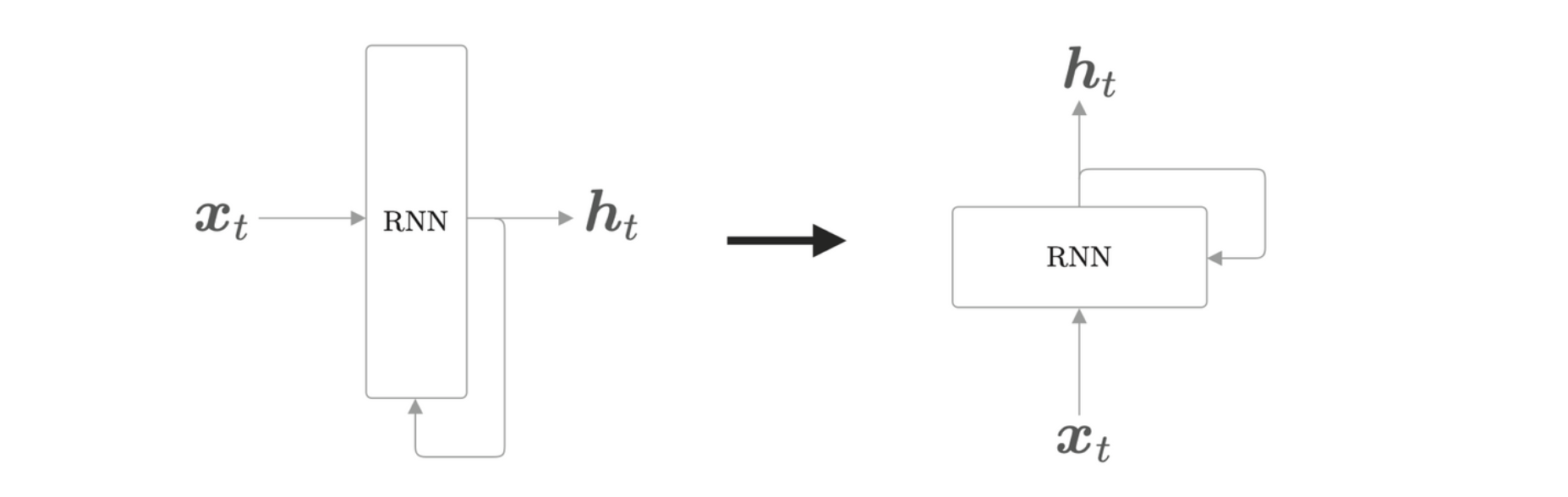
将层从左向右的方向改为从下往上
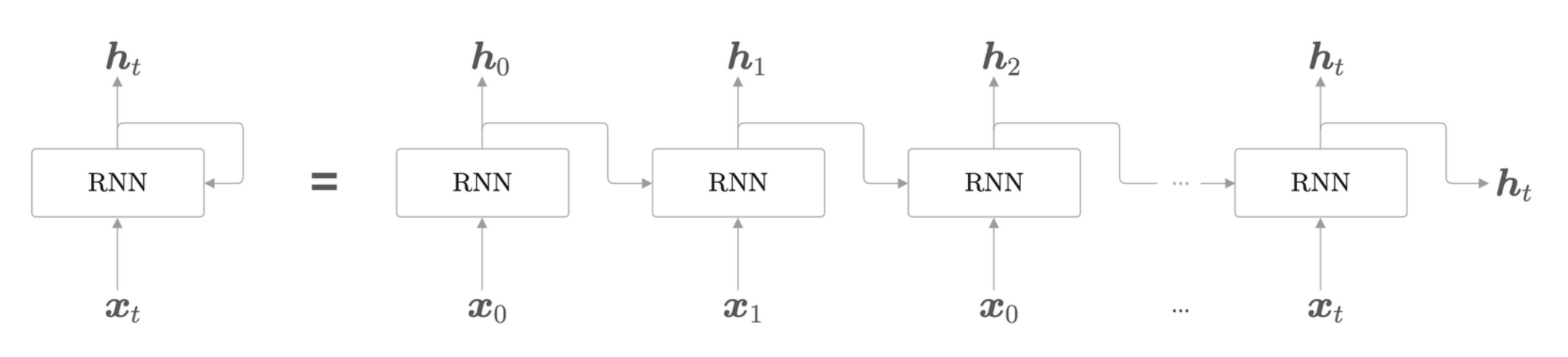
将循环层展开。虽然展开为多个独立的单元,但是这些单元组成一个整体的层。上面的计算可以表示为
\[ \textbf{h}_t = \tanh(\textbf{h}_{t - 1} \textbf{W}_h + \textbf{x}_t \textbf{W}_x + \textbf{b}) \]
其中,\(\textbf{W}_x\) 将输入 \(\textbf{x}\) 转化为输出 \(\textbf{h}\),而 \(\textbf{W}_h\) 将前一个 RNN 层的输出转化为当前时刻的输出。RNN 的 \(\textbf{h}\) 存储状态,时间每前进一步,它就以上式被更新。有时候这个状态被称为隐藏状态(hidden state)。
RNN 的反向传播
将 RNN 展开后,就可以看成是普通 的神经网络,因此常规的反向传播也能在 RNN 内进行。因为这是基于时间的,所以有时候被称为基于时间的反向传播(Backpropagation Through Time,BPTT)。
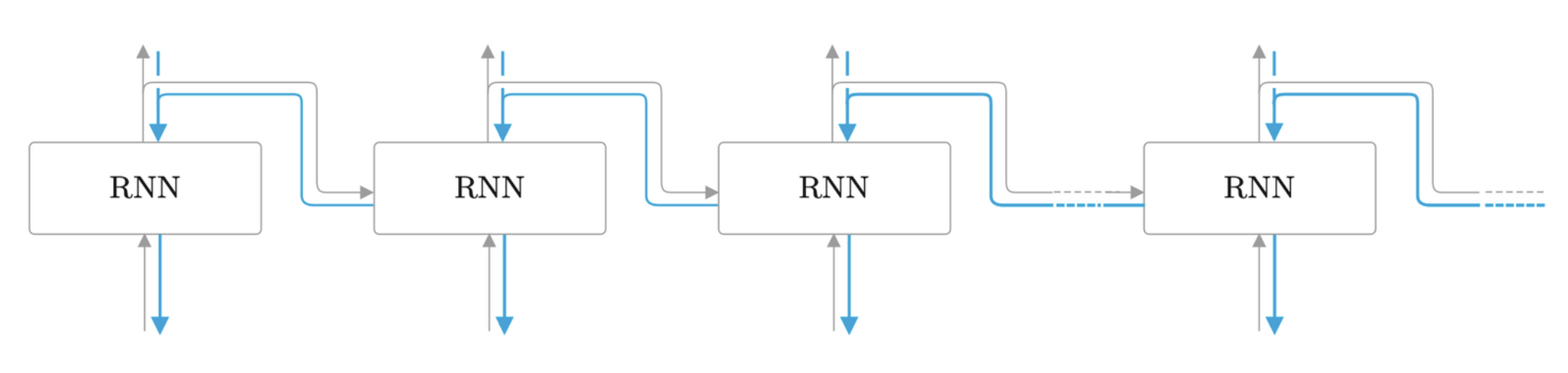
在处理长时序数据时,通常的做法是将网络连接截成适当的长度。具体来说,就是将时间轴方向上过长的网络在合适的位置进行截断,从而创建多个小型网络,然后对截出来的小型网络执行误差反向传播,这个方法称为截断 BPTT(Truncated BPTT)。
需要注意的是,虽然反向传播的链接被截断,但是正向传播的链接不会。

在适当位置截断反向传播的连接。这里,将反向传播的连接中的某一段 RNN 层 称为“块”(块的背景为灰色)
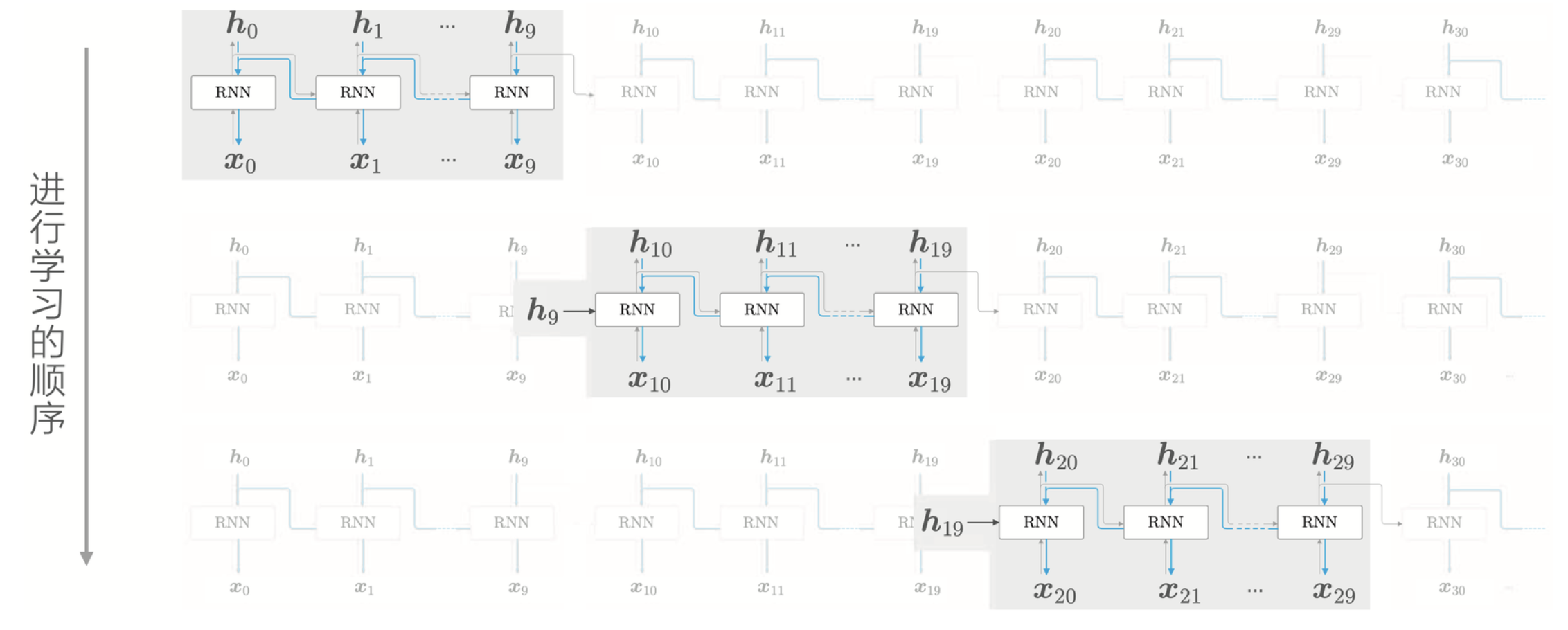
可以注意到,即使分成了区块,正向传播的时候还是需要前一个区块的输出作为输入的,即 \(\textbf{h}_9\) 和 \(\textbf{h}_{19}\),也就是说正向传播是不会截断的,但是对于反向传播来说,只会单纯在块内进行。
Truncated BPTT 的 mini-batch 学习
假设有长度为 1000 的时序数据,以时间长度为 10 为单位进行截断,如果要进行批次为 2 的学习,则需要平移批次数据。第一批由第 1 笔样本开始按顺序输入,第二批由第 501 笔数据开始顺序输入。
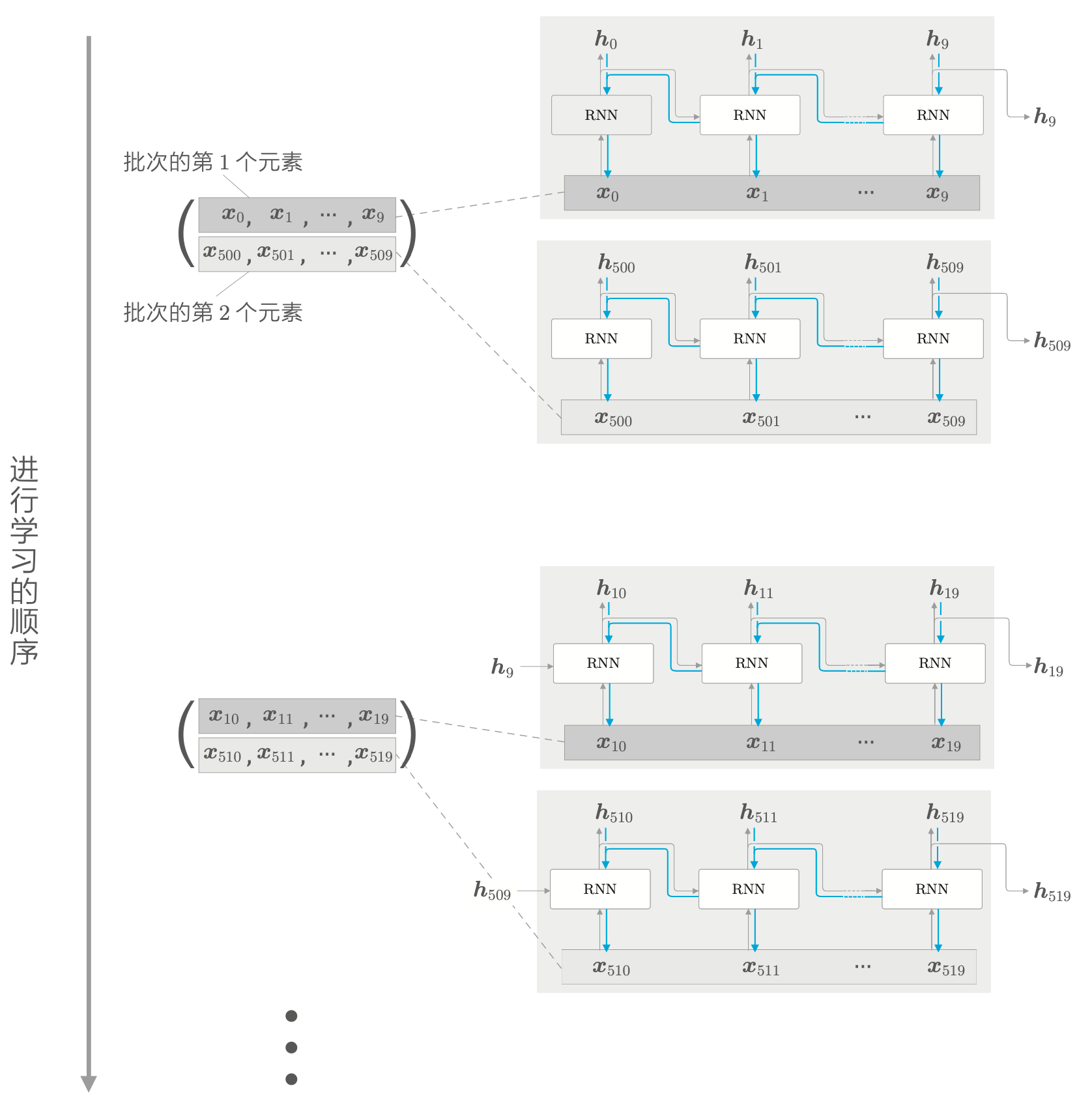
在进行 mini-batch 学习时,在各批次(各样本)中平移输入数据的开始位置
RNN 的实现
考虑到 Truncated BPTT,只需要创建一个在水平方向上长度固定的网络序列即可,RNN 的展开图如下所示。
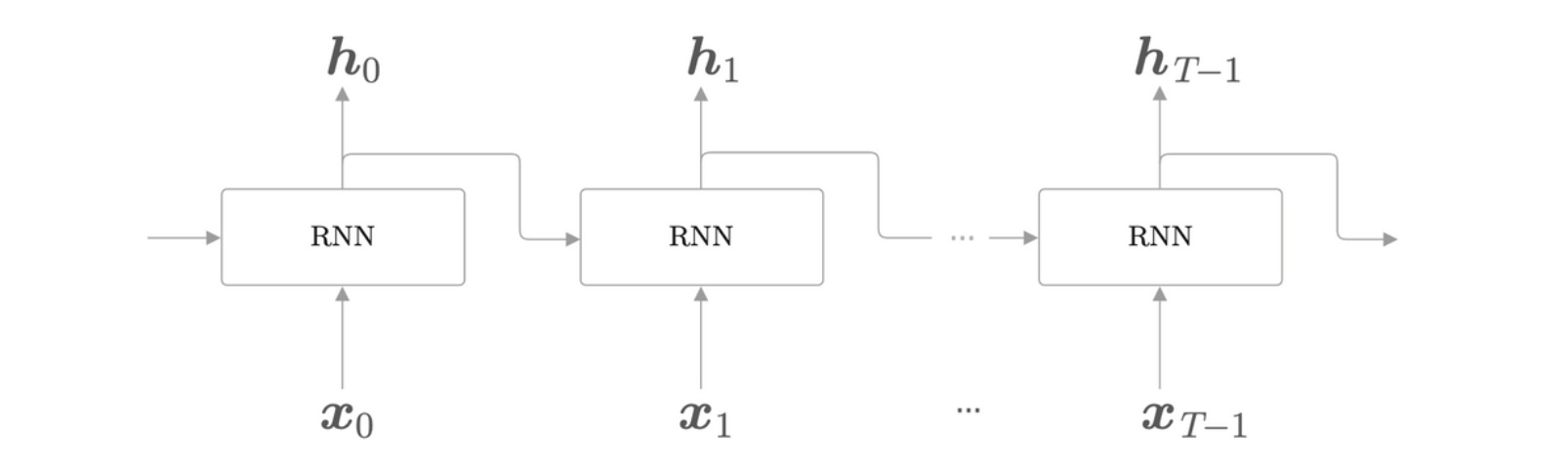
其中长度为 \(T\),也就是隐藏状态有 \(T\) 个。将其整合为一个层,有
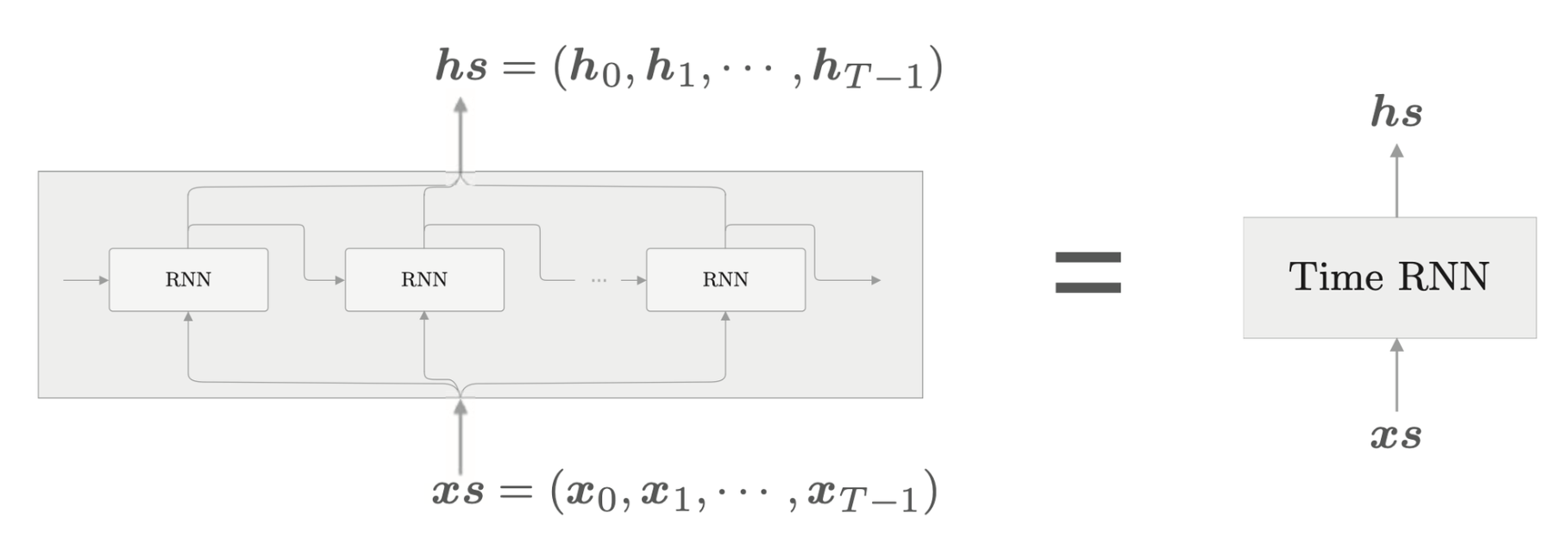
其中处理单步的层称为 RNN 层,一次处理 \(T\) 步的层称为 Time RNN 层。
RNN 层
单步处理的正向传播表达式为
\[ \textbf{h}_t = \tanh(\textbf{h}_{t - 1} \textbf{W}_h + \textbf{x}_t \textbf{W}_x + \textbf{b}) \]
数据以 mini-batch 的形式流入,因此,\(\textbf{x}_t\) 和 \(\textbf{h}_t\) 在行方向上保存各样本数据。假设批大小为 \(N\),输入向量的维数为 \(D\),隐藏向量的维数是 \(H\),则矩阵形状关系如下
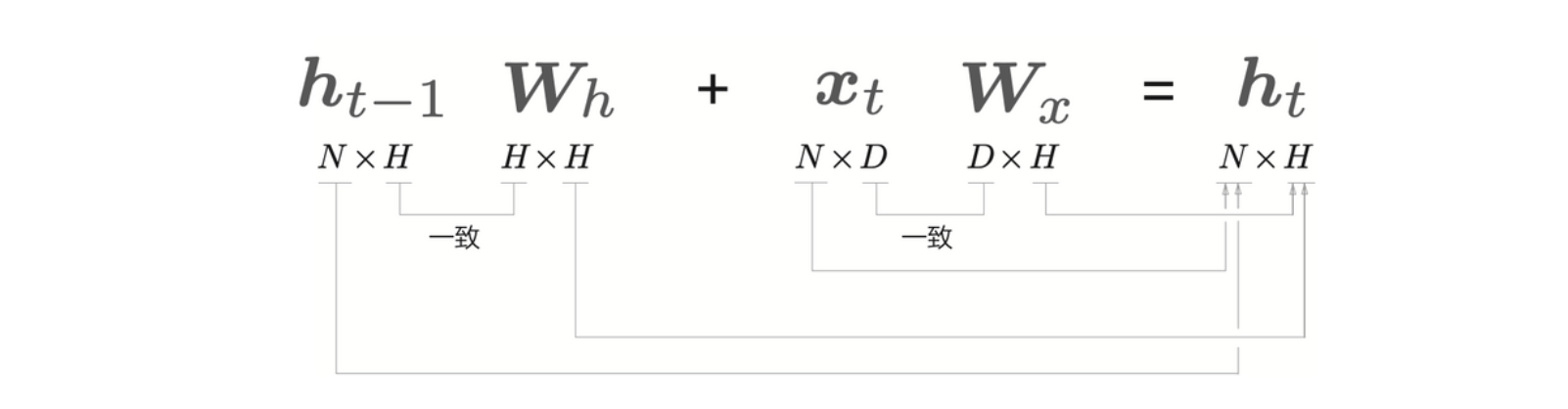
上图省略了偏置。RNN 层的反向传播如下图所示
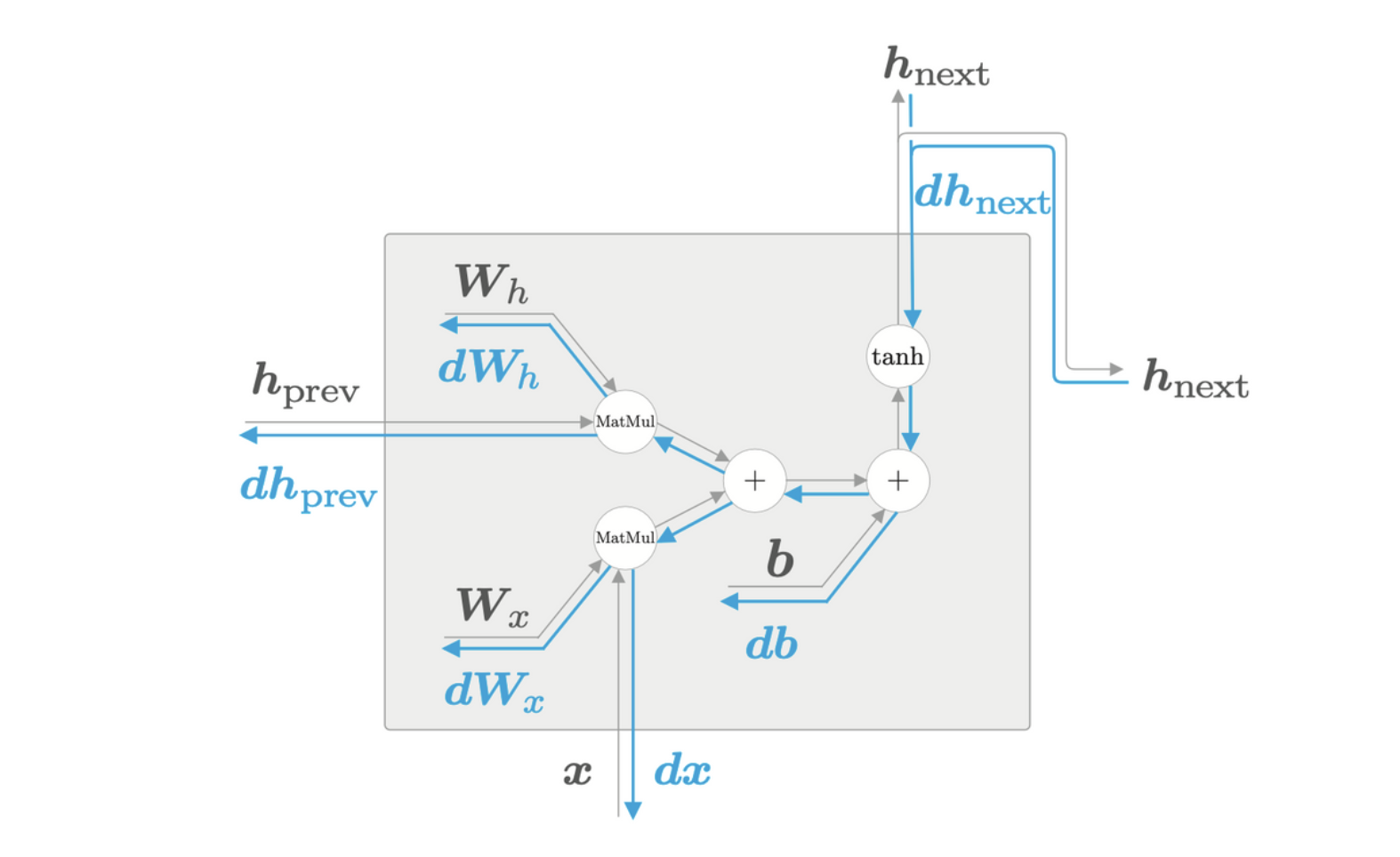
RNN 层的实现如下
class RNN: |
Time RNN 层
Time RNN 层由 \(T\) 个 RNN 层链接起来,RNN 层的隐藏状态 \(\textbf{h}\) 保存在成员变量中。
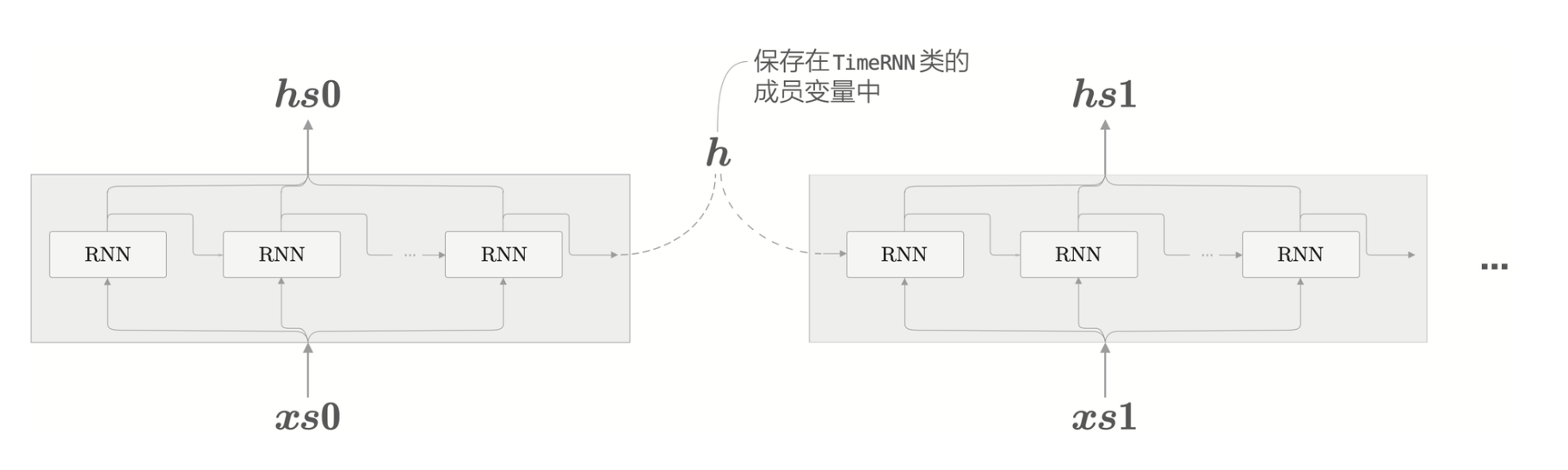
Time RNN 层分有状态和无状态,有状态表示维持 Time RNN
层的隐藏状态,也就是说,无论时序数据多长,Time RNN
层的正向传播都可以不中断地进行。而当其为无状态时,每次调用 Time RNN 的
forward,都会将第一个 RNN 层的隐藏状态初始化为零矩阵。
Time RNN 层的反向传播如下所示
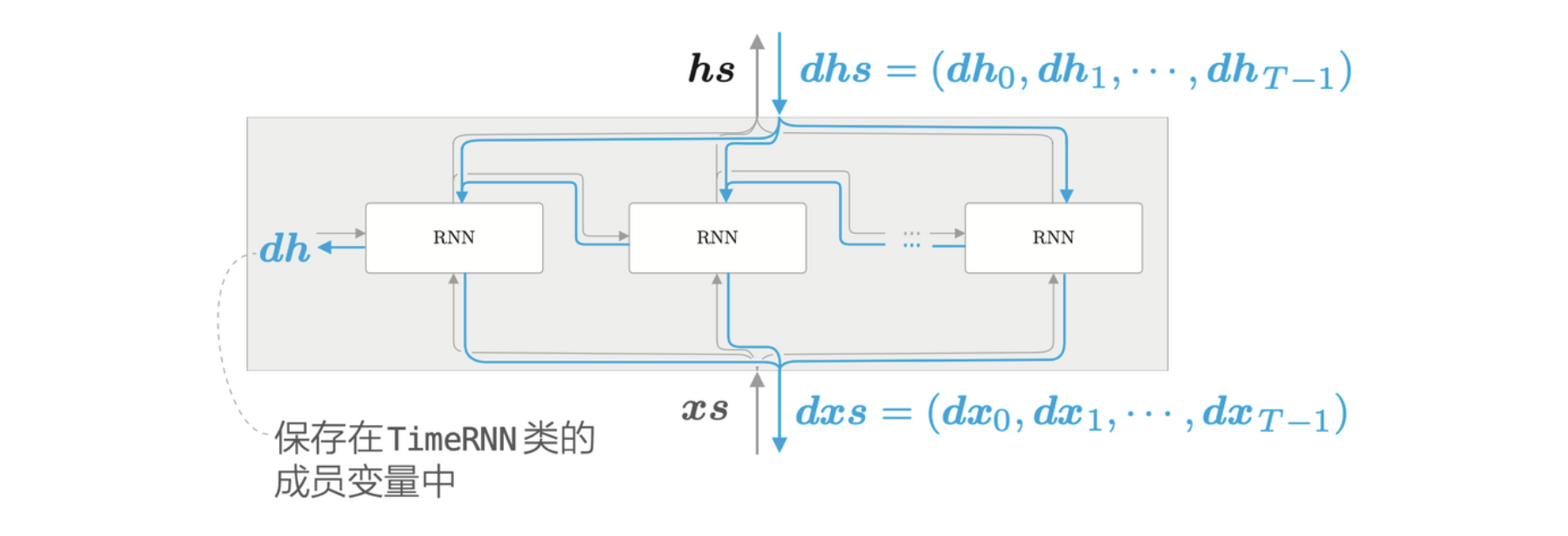
第 \(t\) 个 RNN 层的反向传播
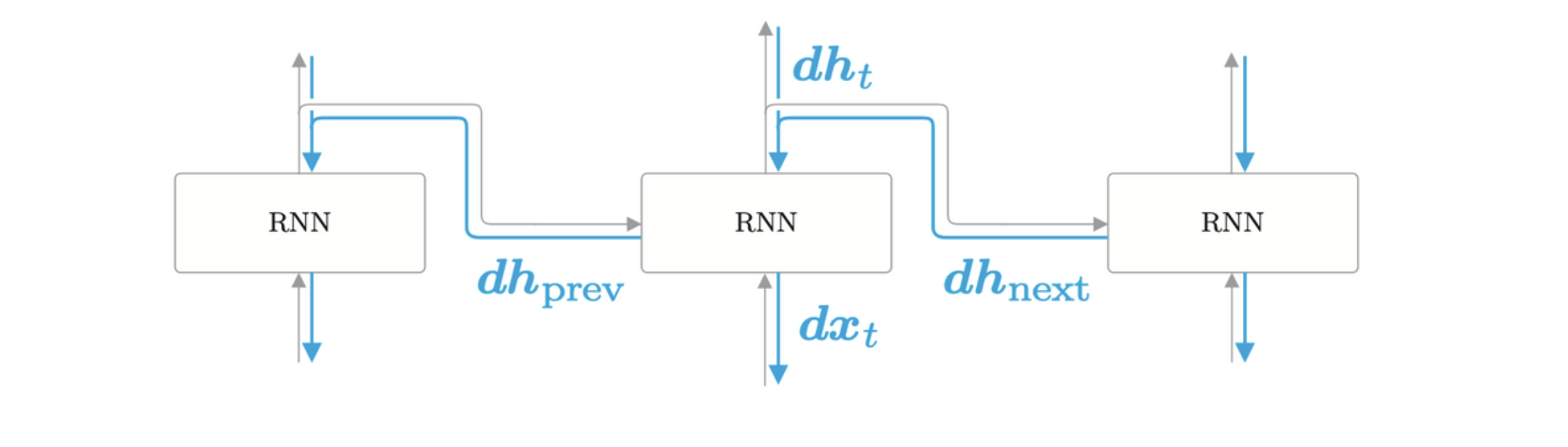
Time RNN 层的实现
Time RNN 层由多个 RNN 层堆叠而成。Time RNN 层会将最后一个 RNN 层的输出作为隐藏状态记录下来。如果 Time RNN 层被设置为无状态,则每次向前传播的时候,这个隐藏状态都会重置为 0,否则则会一直保存这个隐藏状态。
class TimeRNN: |
处理时序数据的层
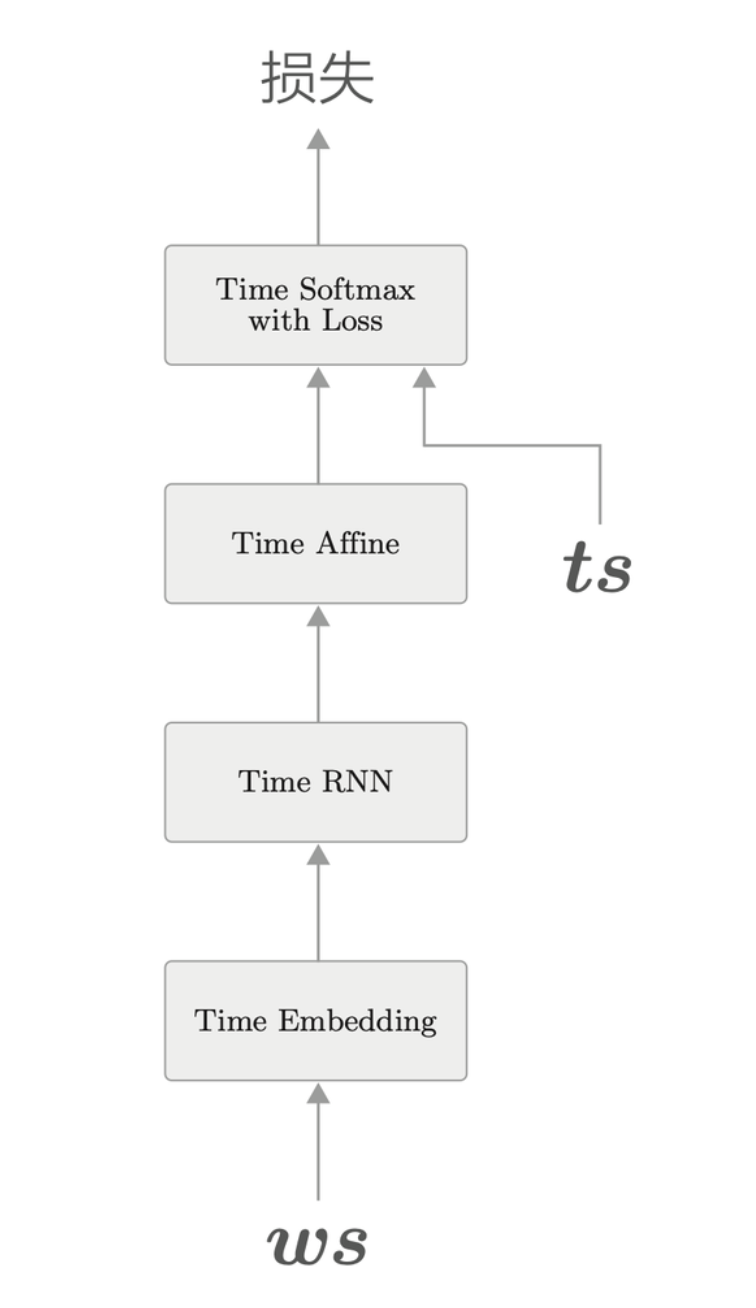
根据已经实现的 RNN 层和整体处理时序数据的 Time RNN 层,可以实现基于 RNN 的语言模型。基于 RNN 的语言模型称为 RNNLM。
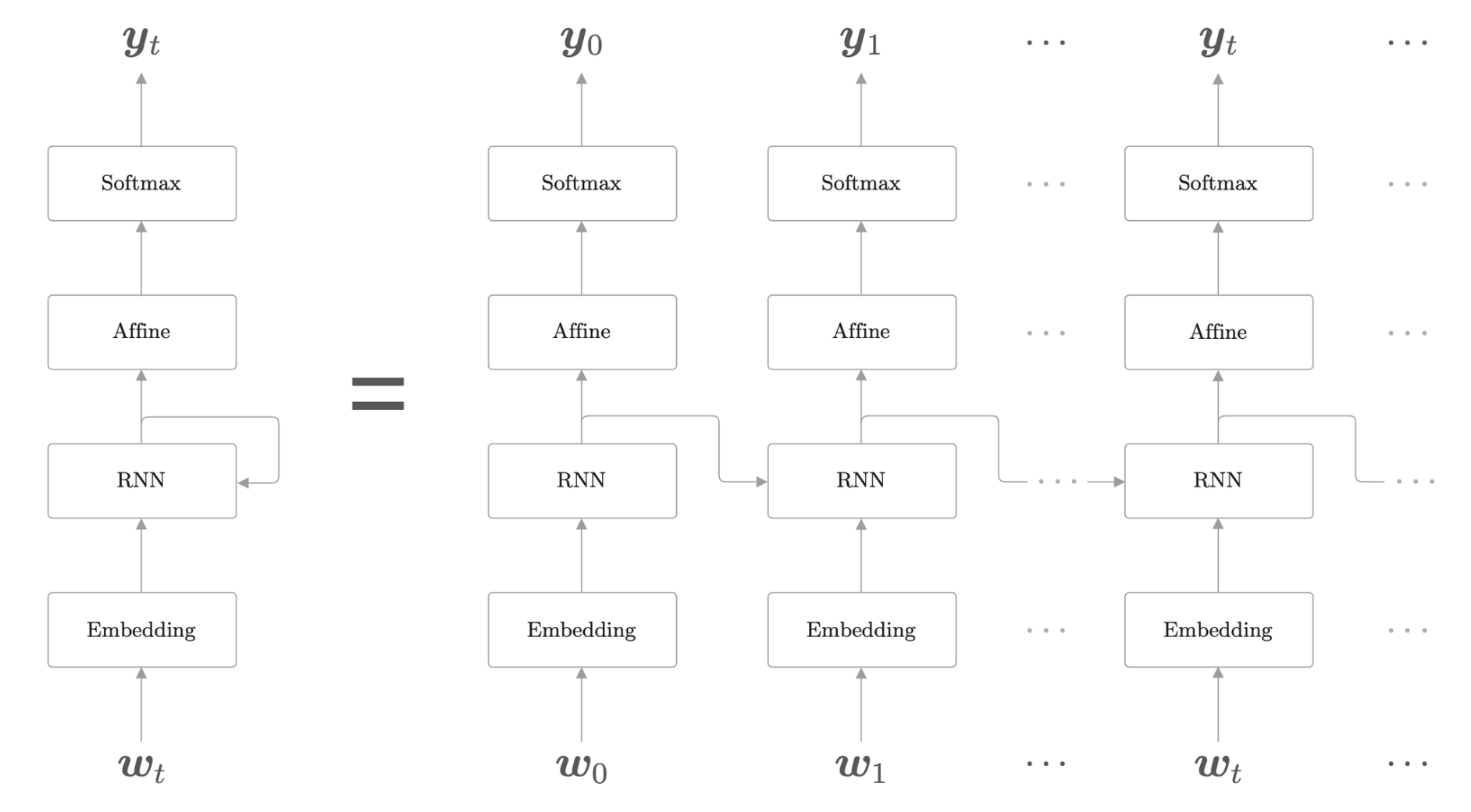
RNNLM 全貌图
左图为 RNNLM 的层结构,右图是基于时间轴的展开网络。
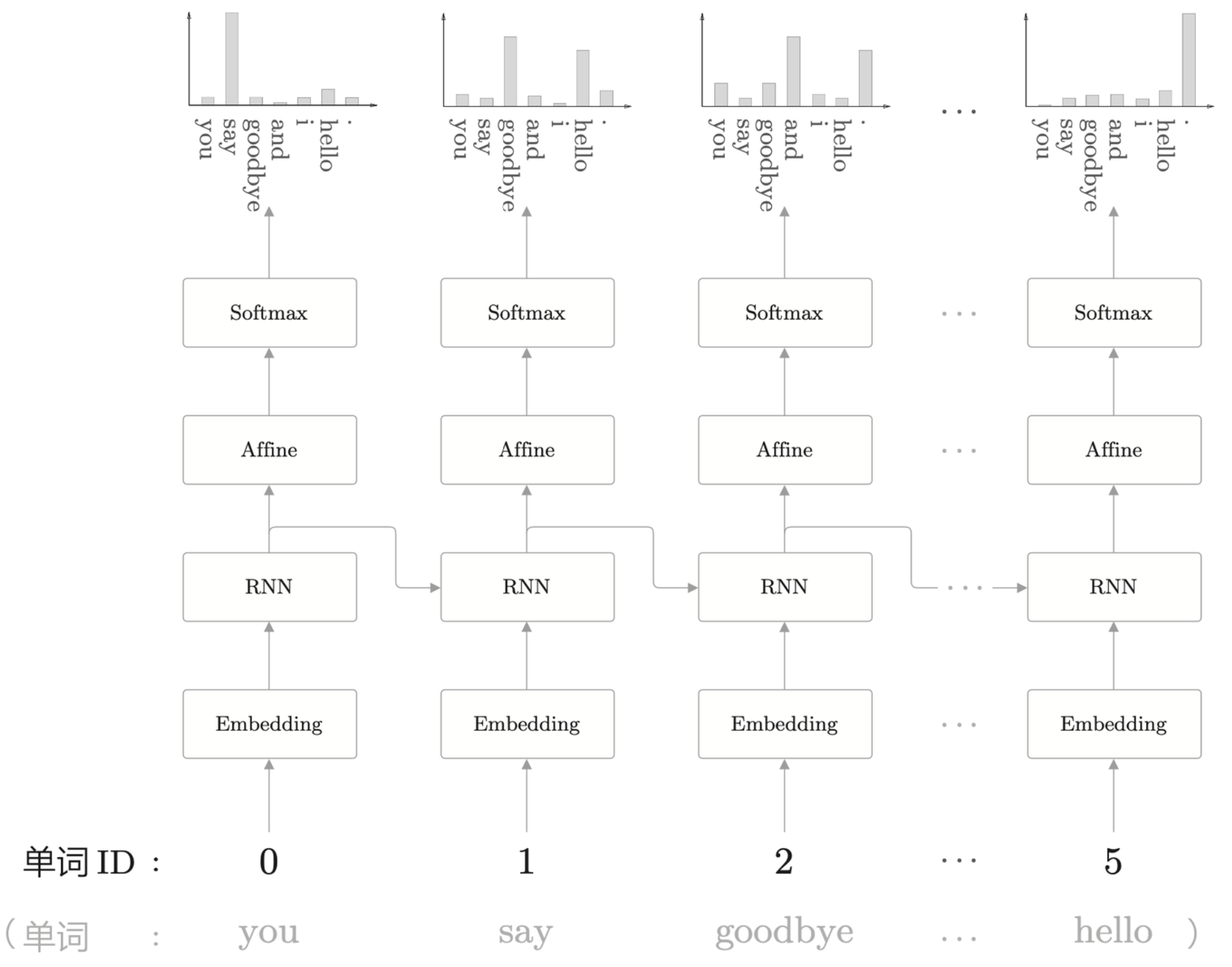
向上面的网络输入“you say goodbye and i say hello”,可以得到
通过实现各个层的 Time 版本,可以组合为整体的时序神经网络。
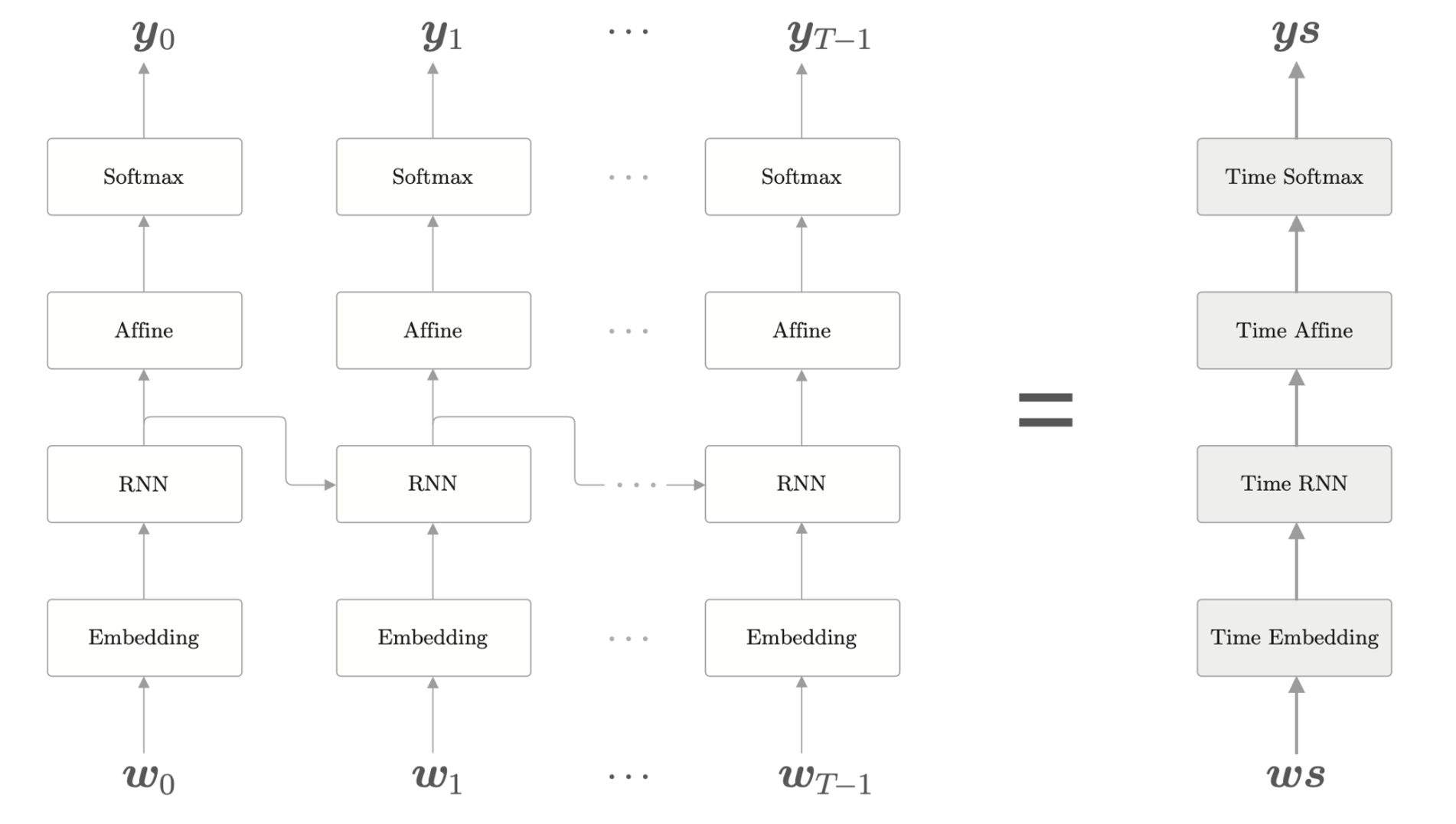
Time 层的实现
RNNLM 的学习和评价
RNNLM 的架构如右图所示,主要是将上面提到的各个层转化为支持时序数据的实现然后堆叠起来。
其中 TimeEmbedding
学习单词的分布式权重,TimeRNN
学习输入的时序特征,TimeAffine 则将输出整合,方便最后的
TimeSoftmax 计算概率以及误差。
语言模型基于给定的已经出现的单词输出将要出现的单词的概率分布。困惑度(perplexity)常被用作评价语言模型的预测性能的指标。
简单地说,困惑度是概率的倒数,困惑度越低越好。由于概率最高为 1,所以困惑度最低就是 1 了。这个值可以看成是分叉度。当困惑度为 1 的时候,分叉度就是 1,意味着下一个可能出现的单词的候选个数位 1。如果概率是 0.25,就意味着困惑度为 4,意味着候选单词有 4 个了。