Attention
Attention 的结构
基于 Attention 机制,seq2seq 可以像我们人类一样,将“注意力”集中在必要的信息上。
seq2seq 存在的问题
seq2seq 中使用编码器对时序数据进行编码,然后将编码信息传递给解码器。此时,编码器的输出是固定长度的向量。这个固定长度很有问题,意味着很长的文本都会被压缩到一个固定长度的编码中。
编码器改进
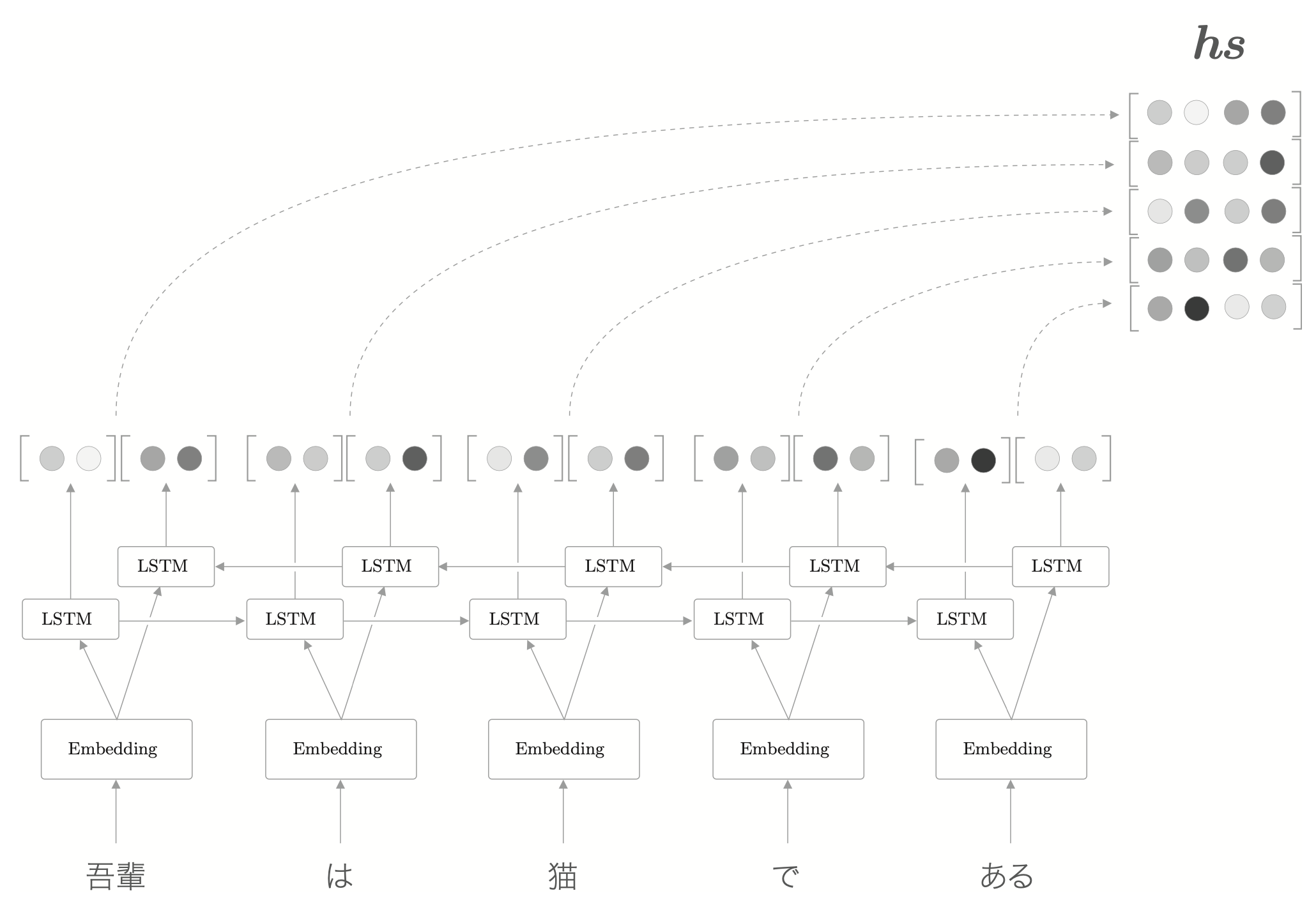
编码器的输出长度应该根据输入文本的长度相应改变。
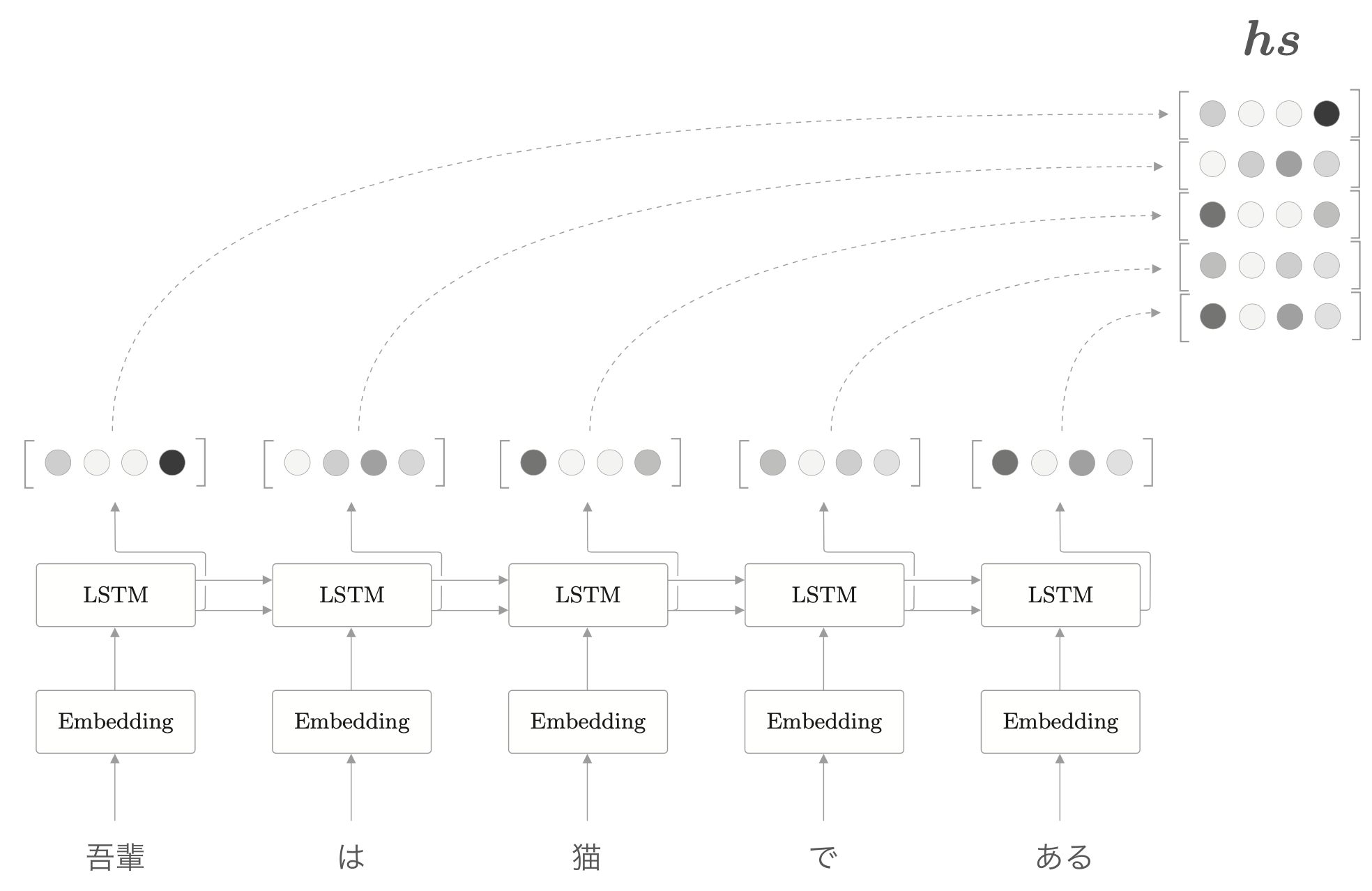
只要将 LSTM 的中间结果也输出出来,就能得到和输入单词数相同的向量。
这个是否带有中间结果的属性在一般的深度学习框架里都有,在 keras
里,这个对应的是初始化 RNN 的参数 return_sequences。
就上面的例子来说,当输入为“猫”时,LSTM 的输出受到“猫”的影响最大,因此,可以认为此时的隐藏状态里蕴含许多“猫的成分”。按照这样的理解,编码器输出的 \(hs\) 矩阵就可以视为各个单词的向量集合。
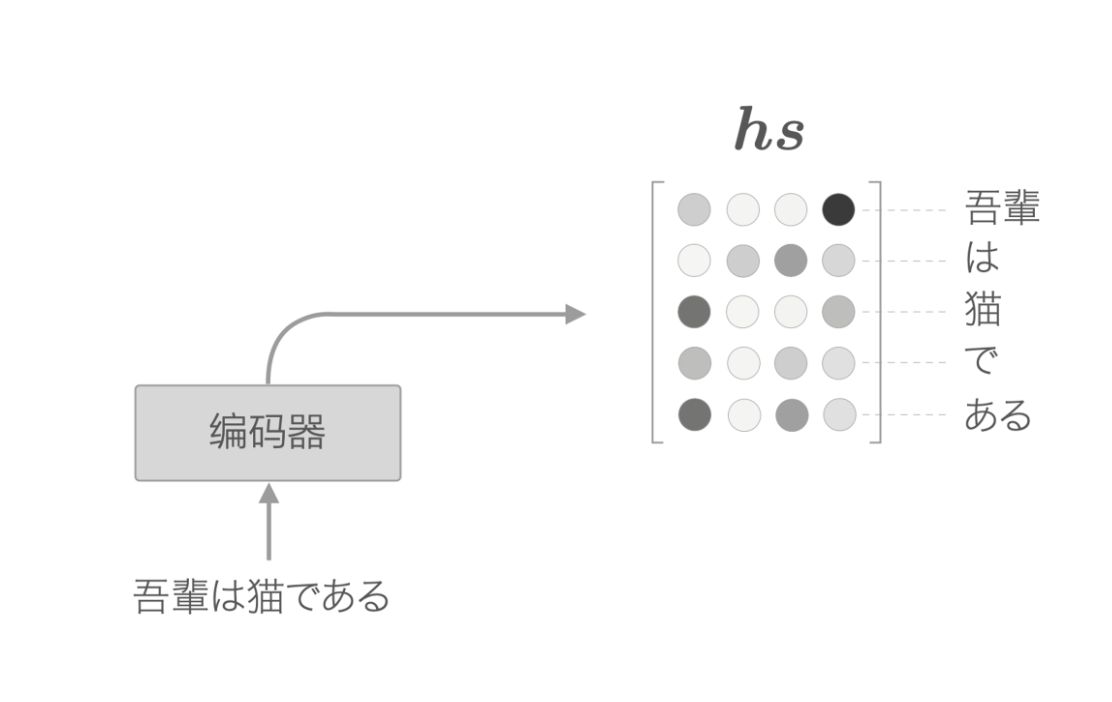
解码器的改进
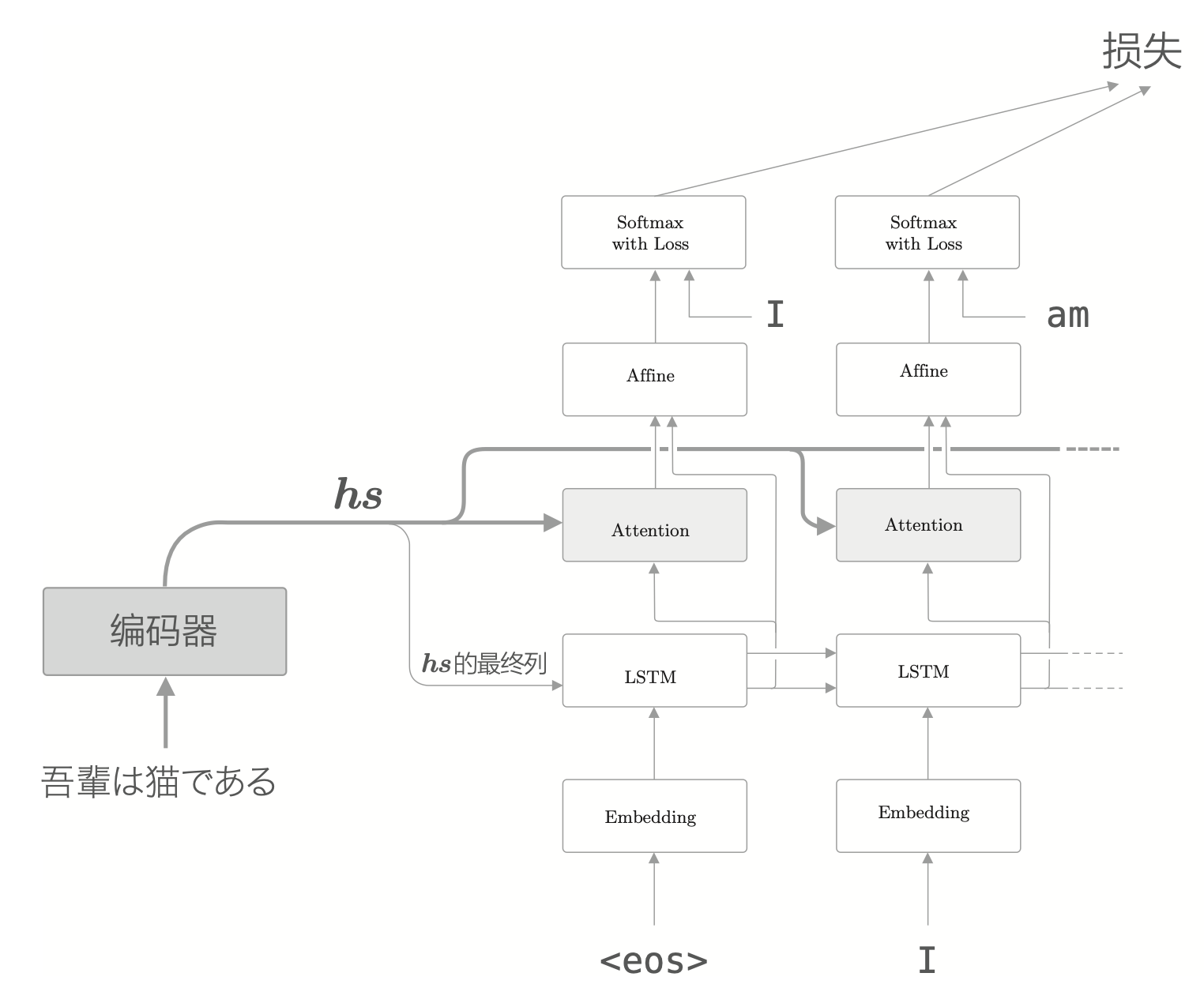
对于不输出隐藏状态的编码器来说,解码器一开始接收到的就只有编码器输出的最后那个隐藏状态,如下图所示。
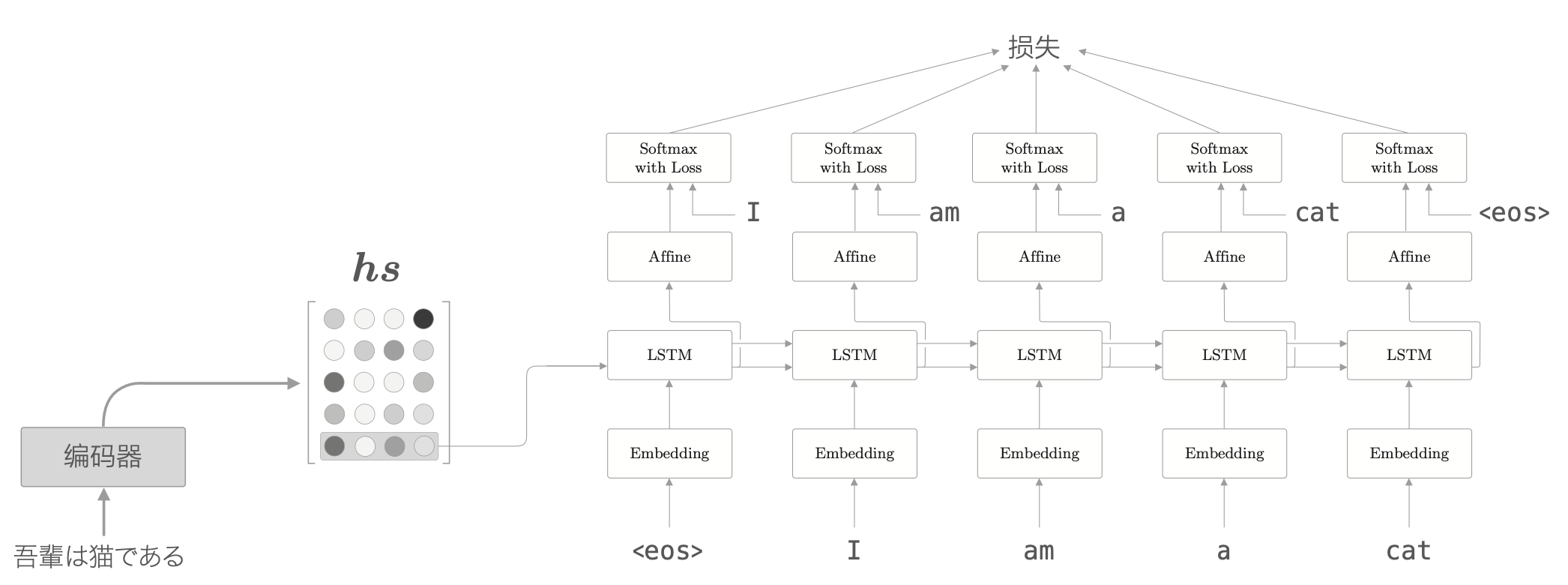
担当我们翻译的时候,肯定要用到诸如“吾輩 = I”或者“猫 = cat”这样的知识,可以认为我们专注于某个单词(或单词集合),随时对这个单词进行转换的。从现在开始,我们的目标是找出与“翻译目标词”有对应关系的“翻译源词”的信息,然后利用这个信息进行翻译。也就是说,我们的目标是仅关注必要的信息,并根据信息进行时序转换,这个机制称为 Attention。其整体架构如下所示。
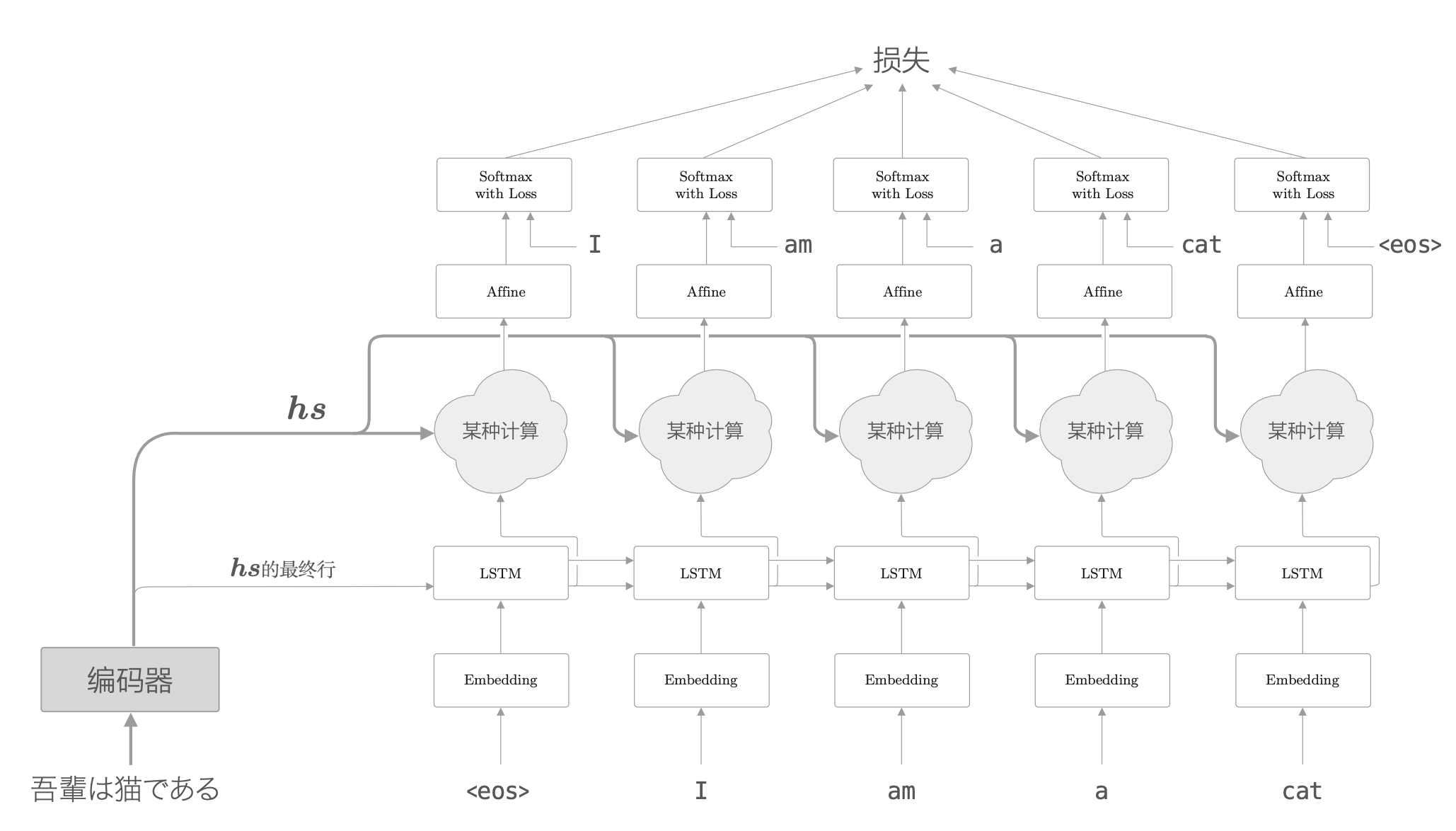
上面的网络所做的工作是提取单词对齐信息,也就是从 \(hs\) 中选出与各个时刻解码器输出的单词有对应关系的单词向量。比如,当出现 “I” 的时候,从 \(hs\) 中选出 “吾輩” 对应的向量。但“选择”这个动作是无法微分的,为了进行反向传播,需要使用一种可微分的方式进行选择。
与其单选,不如全选。对每个单词向量设定一个重要度的权重,用来表示该单词的重要程度,就能实现这种可微分的选择。
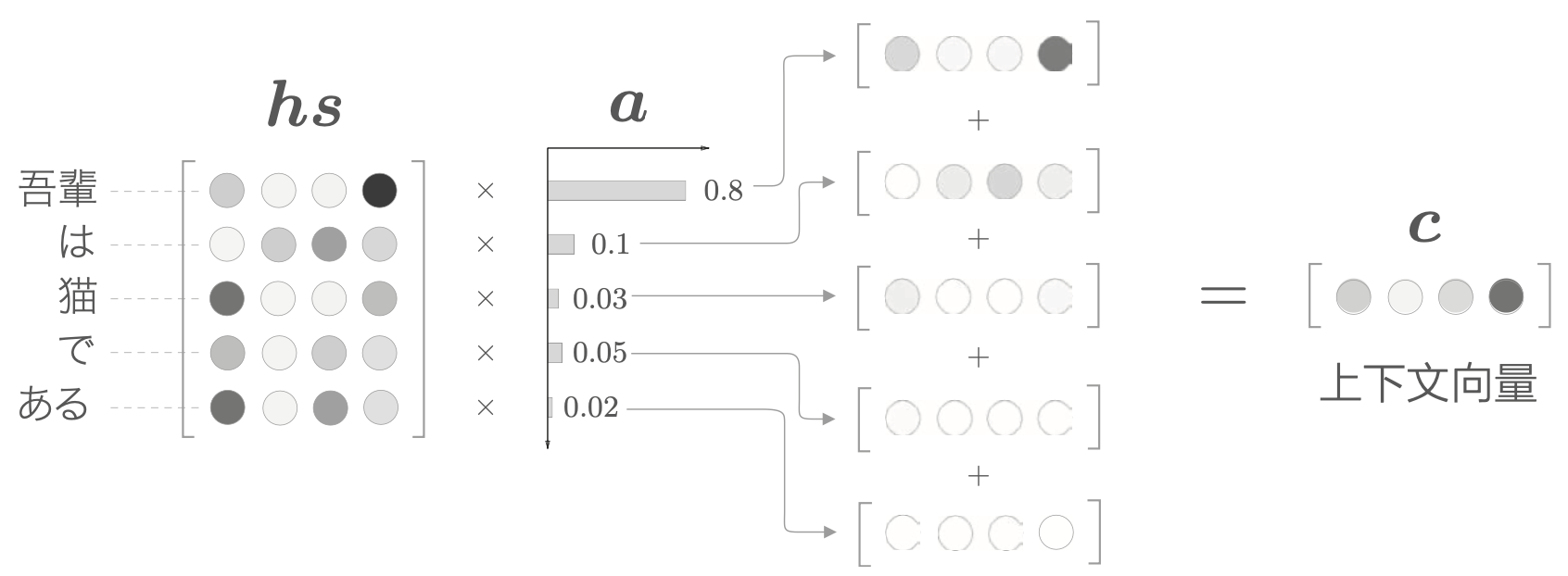
有了表示各个单词重要度的权重 \(a\),就可以通过加权和获得上下文向量。这个 \(a\) 是通过学习的方式学习出来的。
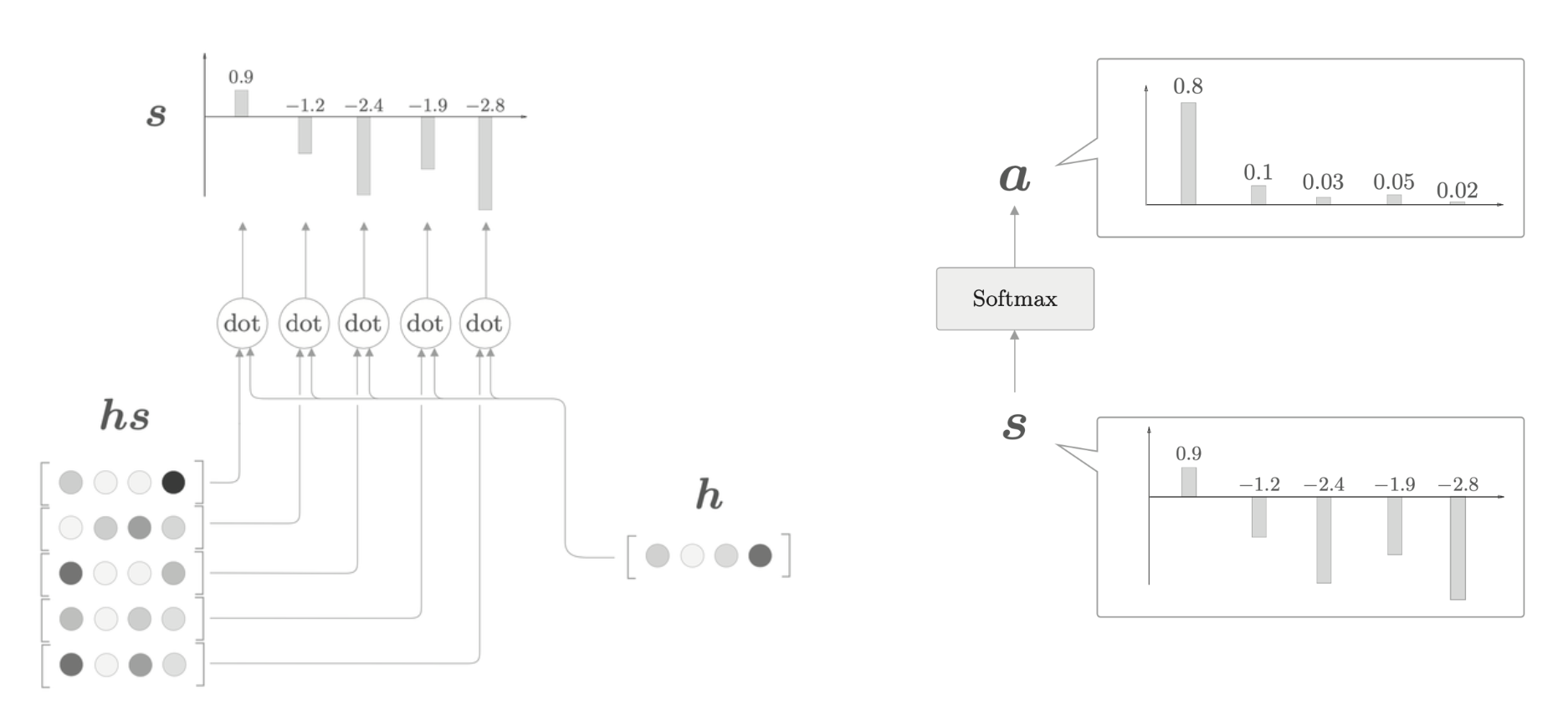
通过内积可以算出 \(h\) 和 \(hs\) 的各个单词向量之间的相似度,并将其结果表示为 \(s\),然后最后对 \(s\) 进行 softmax 正规化,得到 \(a\)。
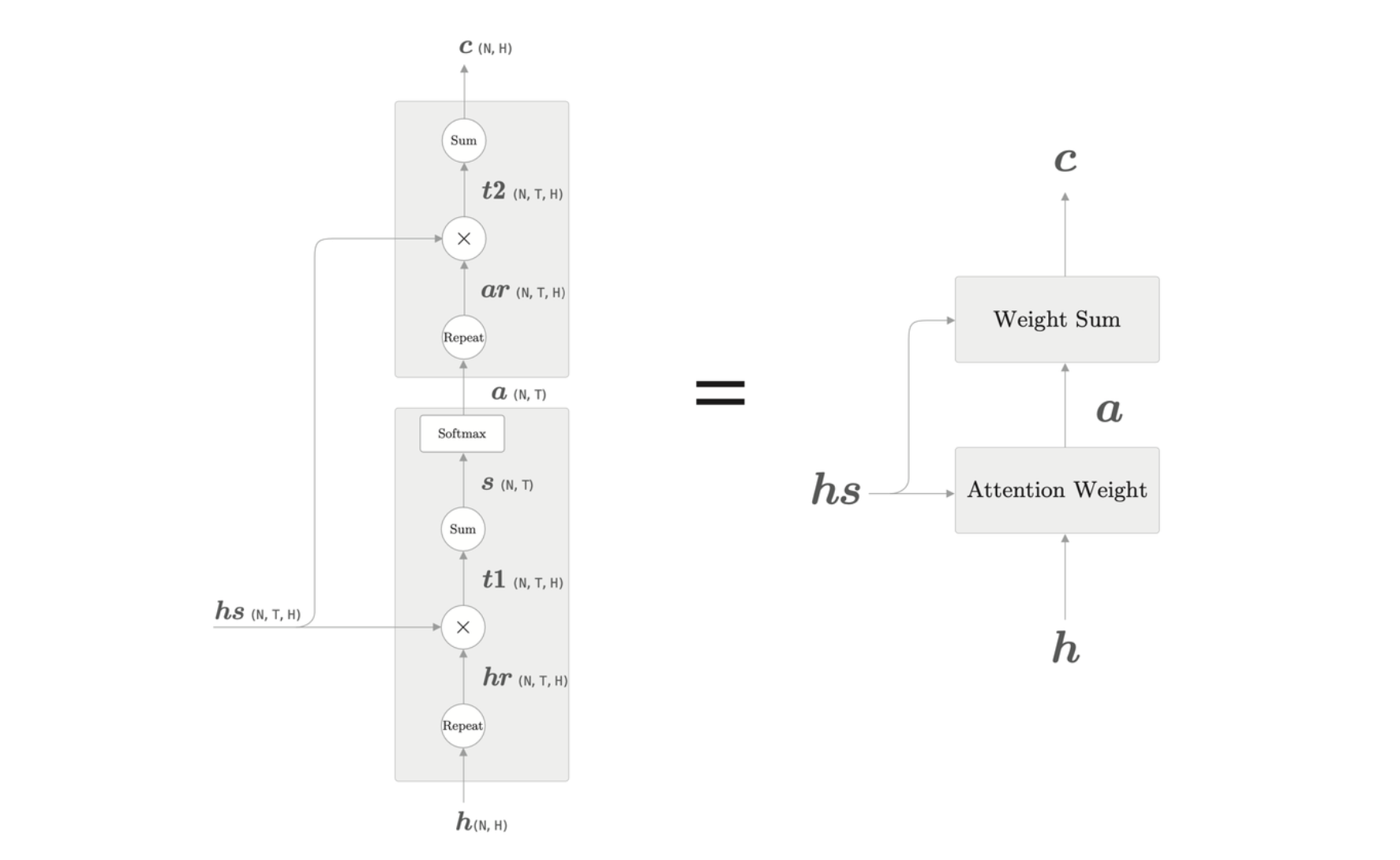
整体架构图如下所示,其中 Attention Weight 关注编码器输出的各个单词向量 \(hs\),并计算各个单词的权重 \(a\),然后,Weight Sum 层计算 \(a\) 和 \(hs\) 的加权和,并输出上下文向量 \(c\)。这整个计算的层称为 Attention 层。
双向 RNN
为了更均衡地获取序列信息,我们可以构造双向 RNN。
双向 LSTM 拼接各个时刻的两个LSTM 层的隐藏状态,将其作为最后隐藏状态的向量。通过这样双向处理,各个单词对应的隐藏状态向量可以从左右两个方向聚集信息。
Attention 层的使用方式
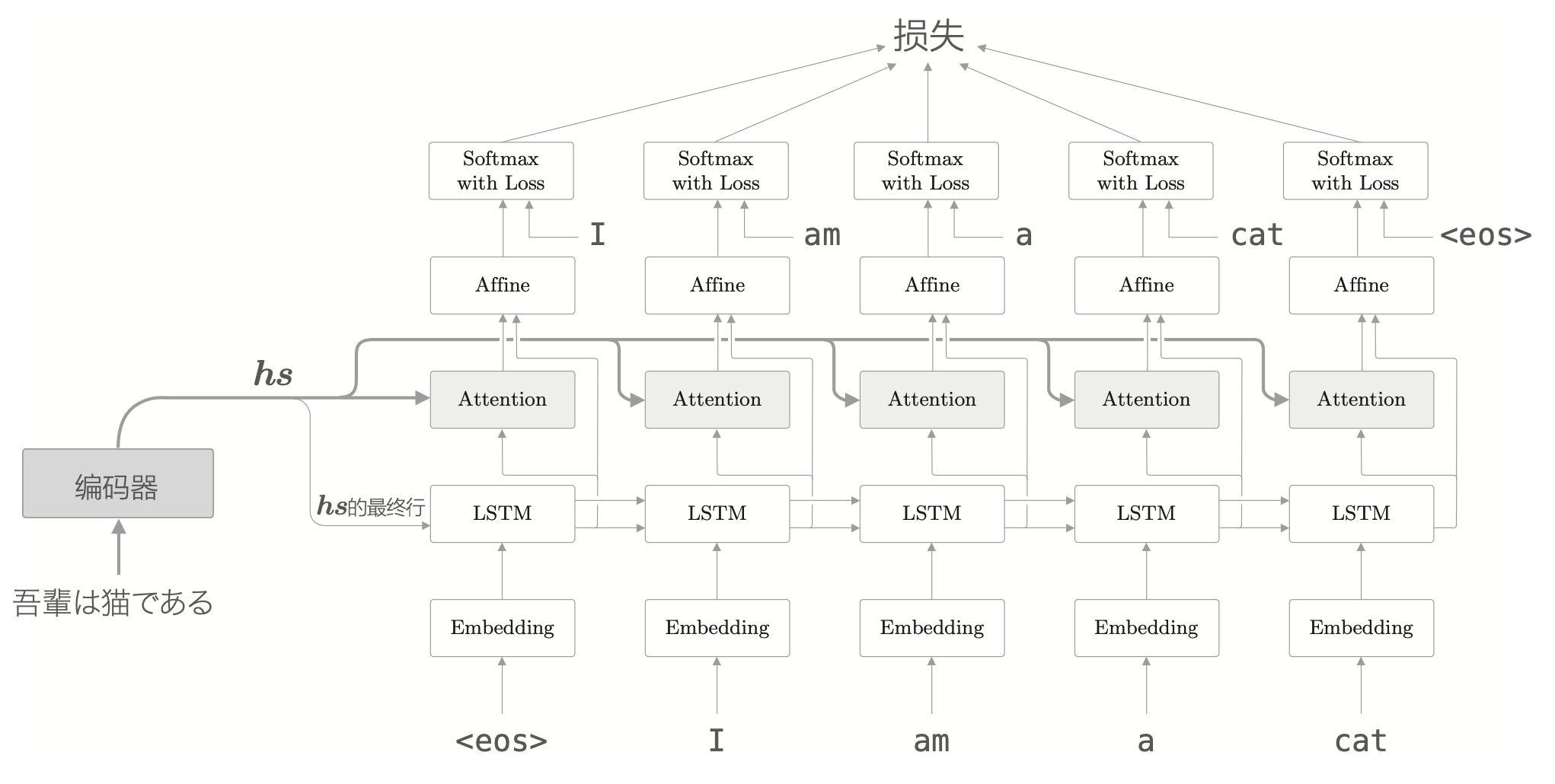
最基础的 Attention 层使用的时候会放在 LSTM 与 Affine 层之间。这时候使用上下文信息的是 Affine 层。
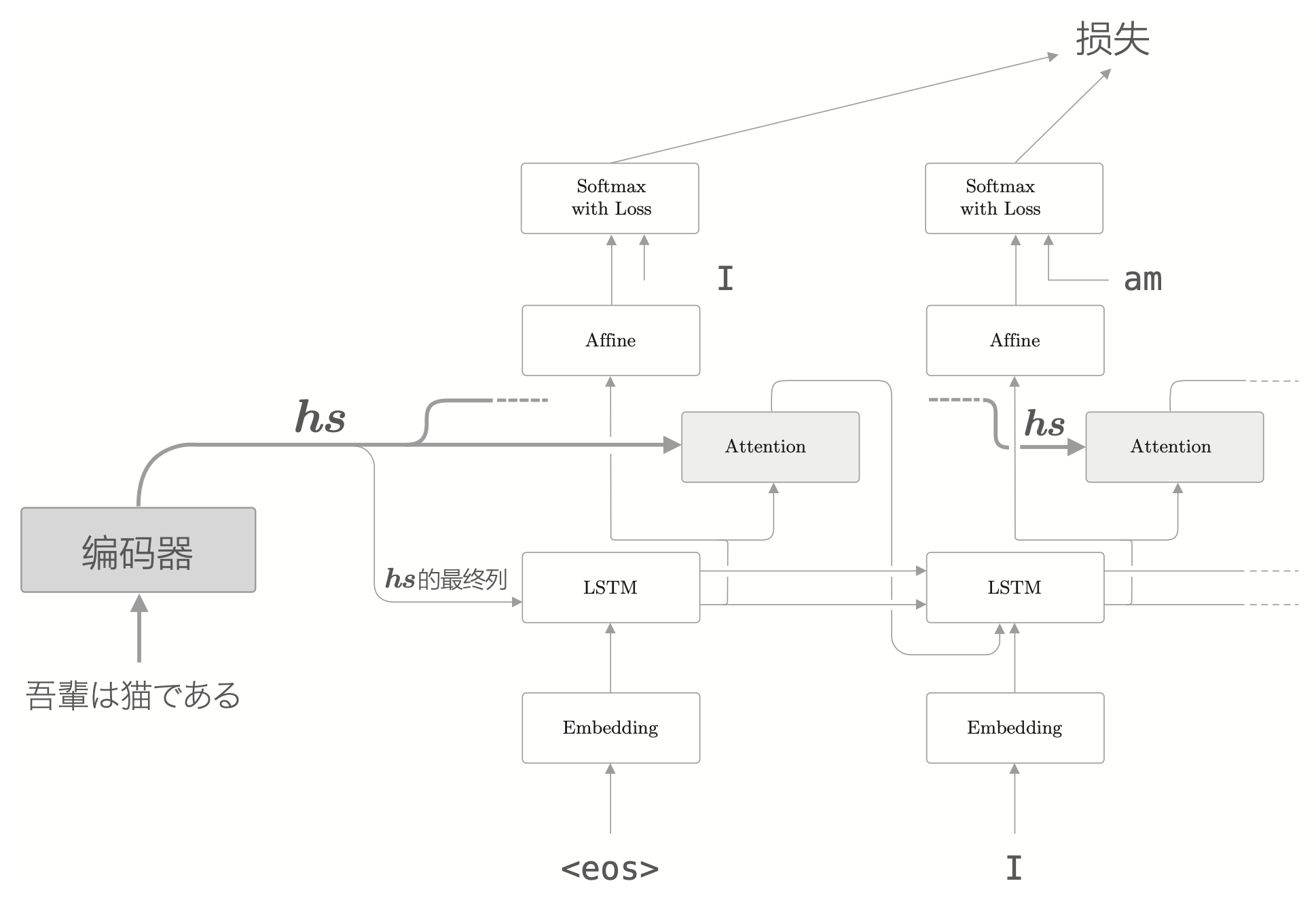
如果使用下图的方式,Attention 层的输出直接作为 LSTM 层的输入,则使用上下文信息的就是 LSTM 层了。
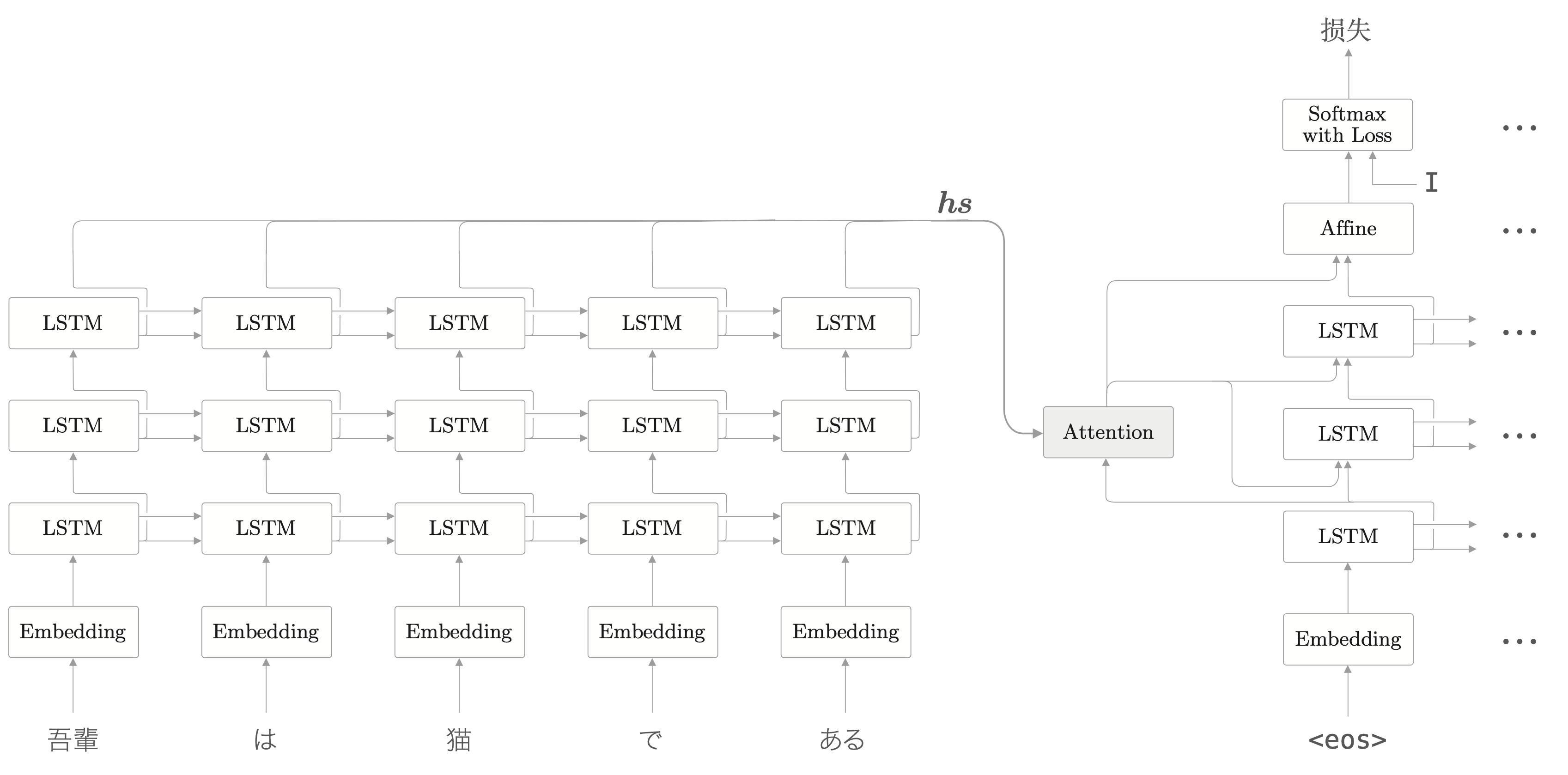
多层的时候使用 Attention 层如下图所示。
Attention 的应用
Attention 本身是一个独立的想法,可以在不同的场景下使用。
GNMT
机器翻译的历史,从“基于规则 当翻译”到“基于用例的翻译”,再到“基于统计的翻译”。现在,神经机器翻译(Neural Machine Translation)取代了这些过去的技术。
谷歌翻译在 2016 年开始将神经机器翻译用于实际的服务,其系统称为 GNMT(Google Neural Machine Translation)。
其架构图如下所示。
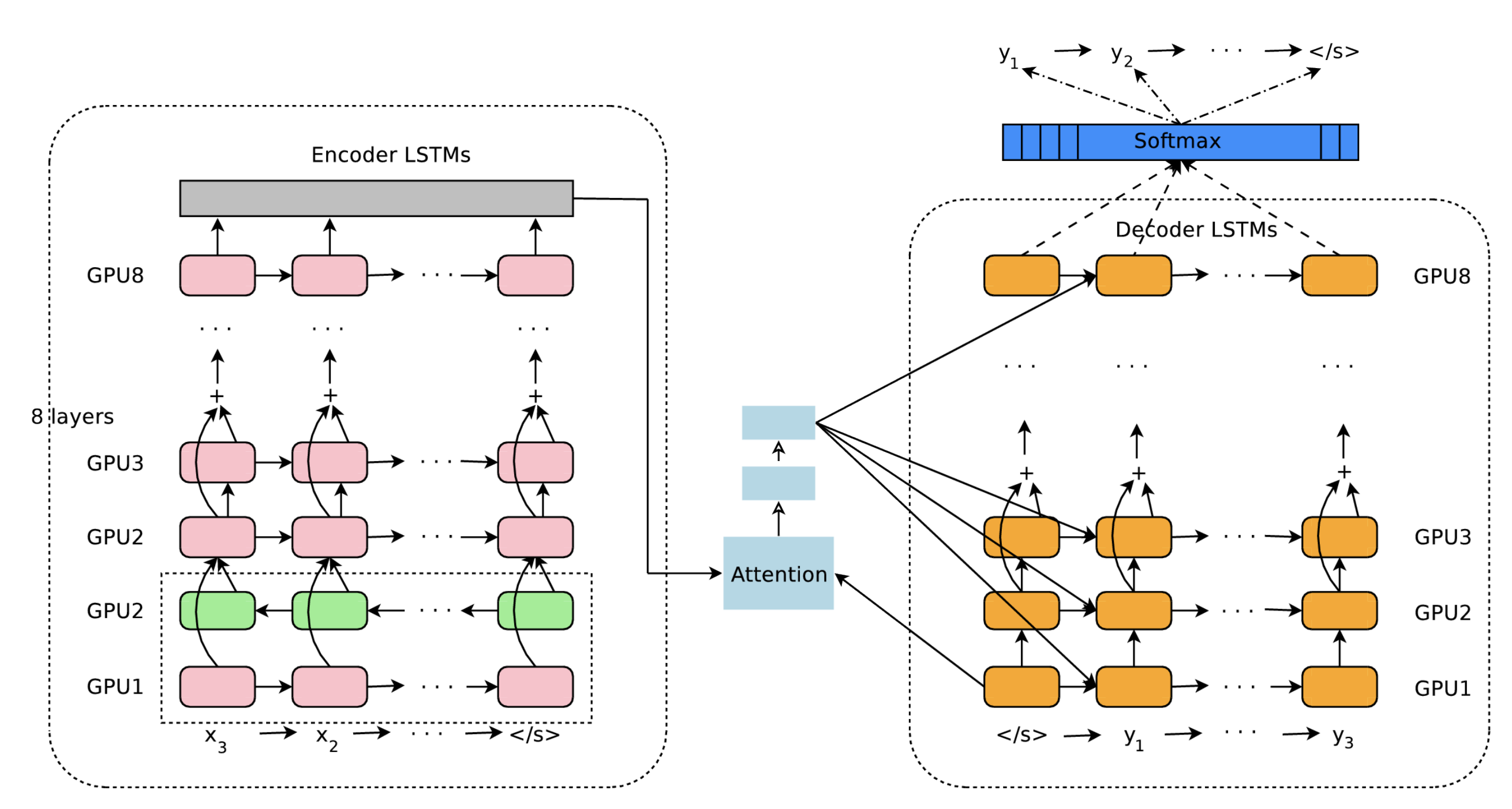
可以看到许多为提高翻译精度而做的改进,比如 LSTM 的多层化,双向 LSTM(编码器的第一层)和 skip connection 等。为了提高学习速度,还进行了多个 GPU 上的分布式学习。
Transformer
RNN 需要基于上一个时刻的计算结果逐步进行计算,因此基本不可能在时间方向上并行计算 RNN。在使用了 GPU 的并行计算环境下进行深度学习,这一点会成为很大的瓶颈,于是就有了避开 RNN 的动机。其中一个著名的模型是 Transformer 模型。Transformer 不用 RNN,而是使用 RNN 进行处理。
Transformer 是基于 Attention 构成的,其中使用了 Self-Attention 的技巧。
使用 Transformer 架构,翻译问题的模型变为下面的样子。
![]()
从图中可以看到是直接使用 Attention 替换了 RNN。图中的 \(Nx\) 表示灰色部分的元素堆叠了 \(N\) 次。
使用 Transformer 可以控制计算量,充分利用 GPU 并行计算带来的好处。
NTM
利用外部存储装置,神经网络也可以获得额外的能力。这类神经网络称为 NTM(Neural Turing Machine)。
在带 Attention 的 seq2seq 中,编码器对输入语句进行编码,然后,解码器通过 Attention 使用被编码的信息,可以理解为基于 Attention,编码器和解码器实现了计算机中的“内存操作”。也可以解释为,编码器将信息写入内存,解码器从内存中读取必要的信息。
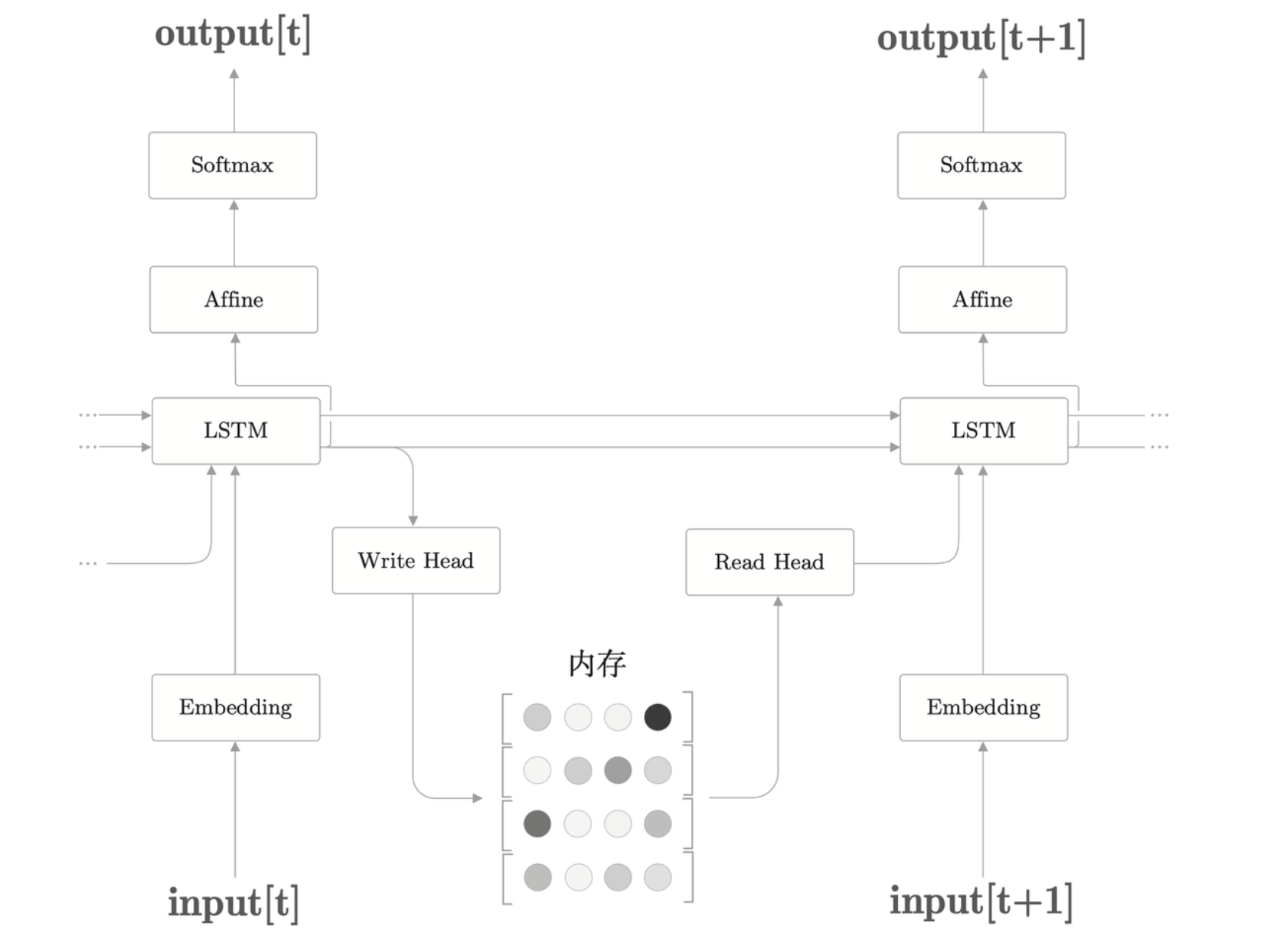
NTM 的层结构里引入了读写头,Write Head 和 Read Head,它们进行内存的读写。为了模仿计算机的内存操作,NTM 的内存操作使用了两个 Attention,分别是“基于内容的 Attention”和“基于位置的 Attention”。