Curiosity-driven exploration
The games that DQN was successful at all gave relatively frequent rewards during game play and did not require significant long-term planning. But some other games, let’s say give a reward after the player finds a key in the room. But it is extremely unlikely that the agent will find the key and get a reward with this random exploration policy.
This problem is called the sparse reward problem. If the agent doesn’t observe enough reward signals to reinforce its actions, it can’t learn.
Tackling sparse rewards with predictive coding
Curiosity can be thought of as a kind of desire to reduce the uncertainty in your environment. One of the first attempts to imbue reinforcement learning agents with a sense of curiosity involved using a prediction error mechanism. The idea was that in addition to trying to maximize extrinsic rewards, the agent would also try to predict the next state of the environment given its action, and it would try to reduce its prediction error.
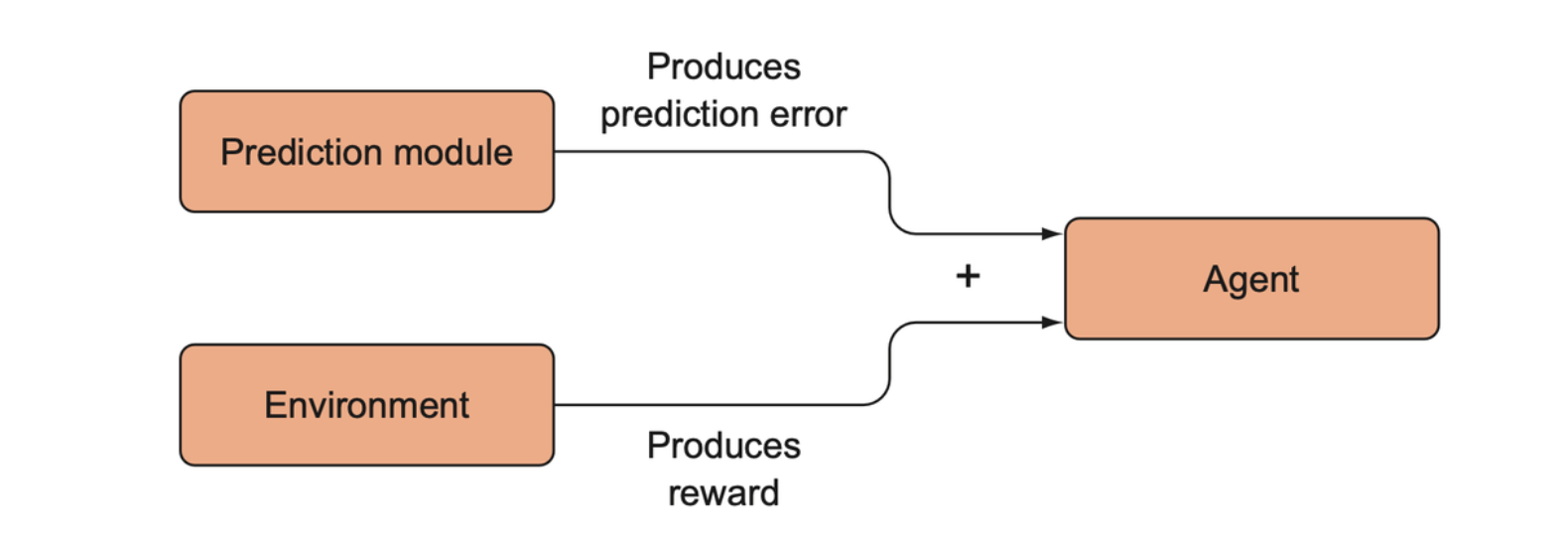
The idea is to sum the prediction error (which will be called intrinsic reward) with the extrinsic reward and use that total as the new reward signal for the environment.
Inverse dynamics prediction
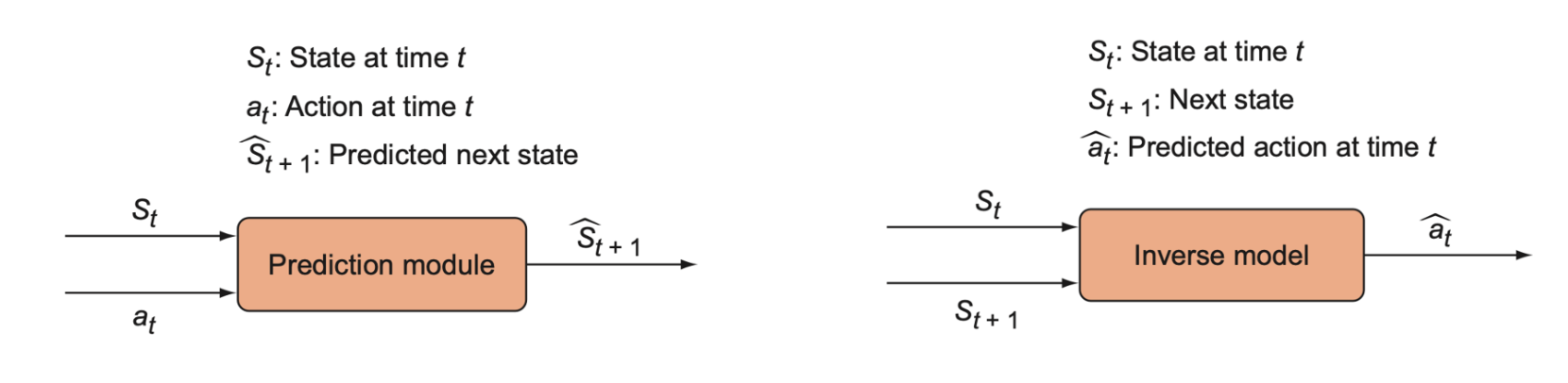
The prediction error module is implemented as a function: \(f: (S_t, a_t) \to \hat{S}_{t+1}\), that takes a state and the action taken and returns the predicted next state. It is predicting the future state of the environment, so we call it the forward-prediction model.
We want to only predict aspects of the state that actually matter, not parts that are trivial or noise. The way to build in the “doesn’t matter” constraint to the prediction model is to add another model called an inverse model, \(g: (S_t, S_{t+1}) \to \hat{a}_t\). This is a function that takes a state and the next state, and then returns a prediction for which action was taken that led to the transition from \(s_t\) to \(s_{t+1}\).
There is another model that is tightly coupled to the inverse model called the encoder model, denoted \(\phi\). The encoder function, \(\phi: S_t \to \tilde{S}_t\), takes a state and returns an encoded state \(\tilde{S}_t\) such that the dimensionality of \(\tilde{S}_t\) is significantly lower than the raw state \(S_t\).
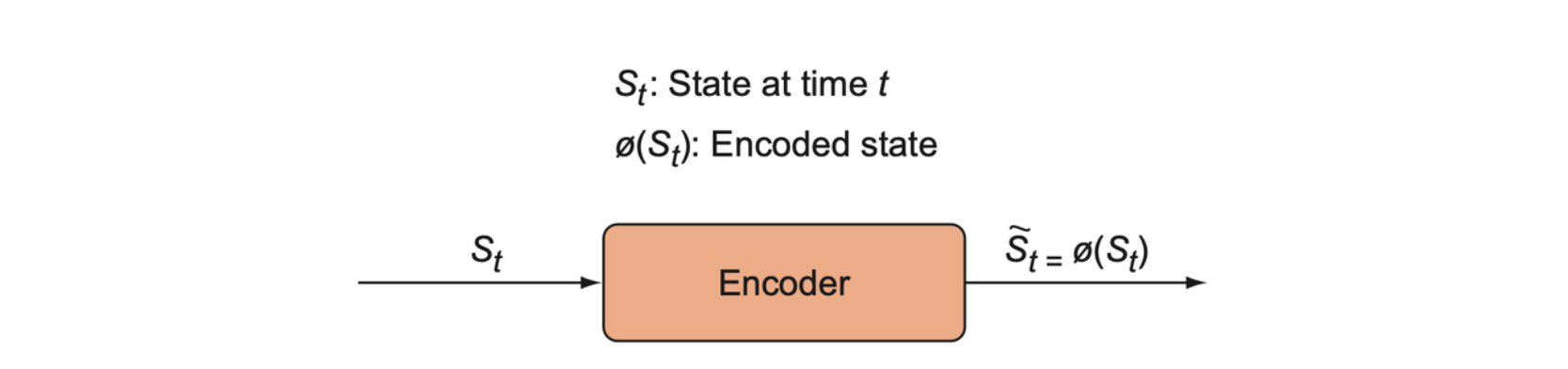
The encoder model is trained via the inverse model because we actually use the encoded states as inputs to the forward and inverse models \(f\) and \(g\) rather than the raw states. That is, the forward model becomes a function, \(f: \phi(S_t) \times a_t \to \hat{\phi}(S_{t+1})\), where \(\hat{\phi}(S_{t+1})\) refers to a prediction of the encoded state, and the inverse model becomes \(g: \phi(S_t) \times \hat{\phi}(S_{t+1}) \to \hat{a}_t\).
The encoder model isn’t trained directly —— it is not an auto-encoder. It is only trained through the inverse model.
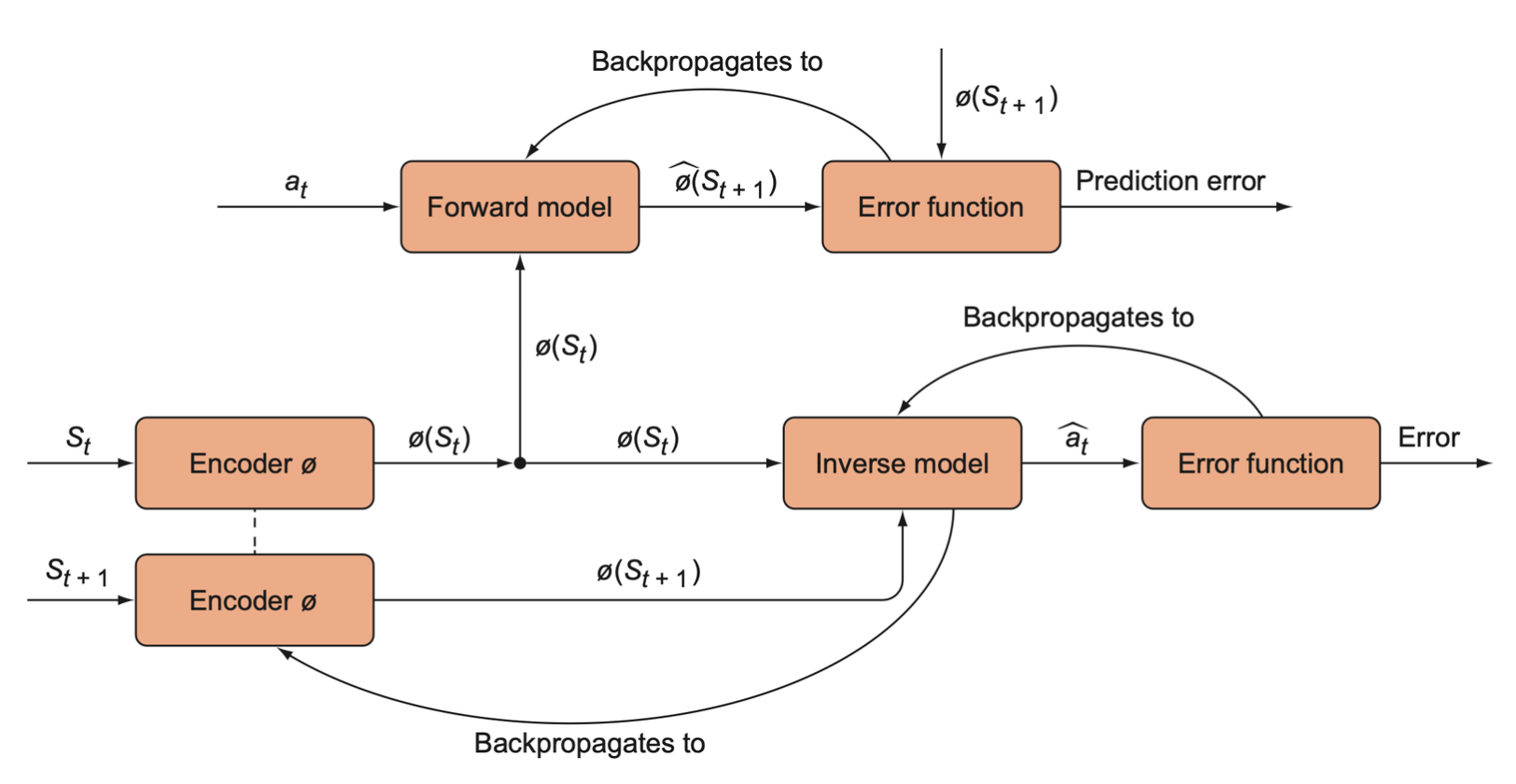
The curiosity module.
- Encode states \(S_t\) and \(S_{t+1}\) into low-dimensional vectors, \(\phi(S_t)\) and \(\phi(S_{t+1})\).
- The encoded states are passed to the forward and inverse models.
- The inverse model backpropagates to the encoded model.
- The forward model is trained by backpropagating from its own error function, but it does not backpropagate through to the encoder.
Setting up Super Mario Bros
The forward, inverse, and encoder models form the intrinsic curiosity module (ICM), which will be implemented below. The ICM generates a new intrinsic reward signal based on information from the environment, so it is independent of how the agent model is implemented. To keep everything simple, we use a Q-learning model.
Install Super Mario Bros by pip.
pip install gym-super-mario-bros |
After installing, it can be used as
from nes_py.wrappers import JoypadSpace |
render_mode specifies how the game is rendered. In most
of training processes below, the render_mode is
rgb_array, which returns an array of a frame in the game,
whose shape is (x, y, 3)
Since gym now becomes gymnasium, all the
APIs have breaking changes, apply_api_compatibility should
be set to True.
Preprocessing and the Q-network
The raw state is an RGB video frame with dimensions (240, 256, 3), which is unnecessarily high-dimensional and would be computationally costly for no advantage. We will convert these RGB states into grayscale and resize them to 42x42 to allow our model to train much faster.
import matplotlib.pyplot as plt |
Then we will use the last three frames as a single state. This gives our model access to velocity information.
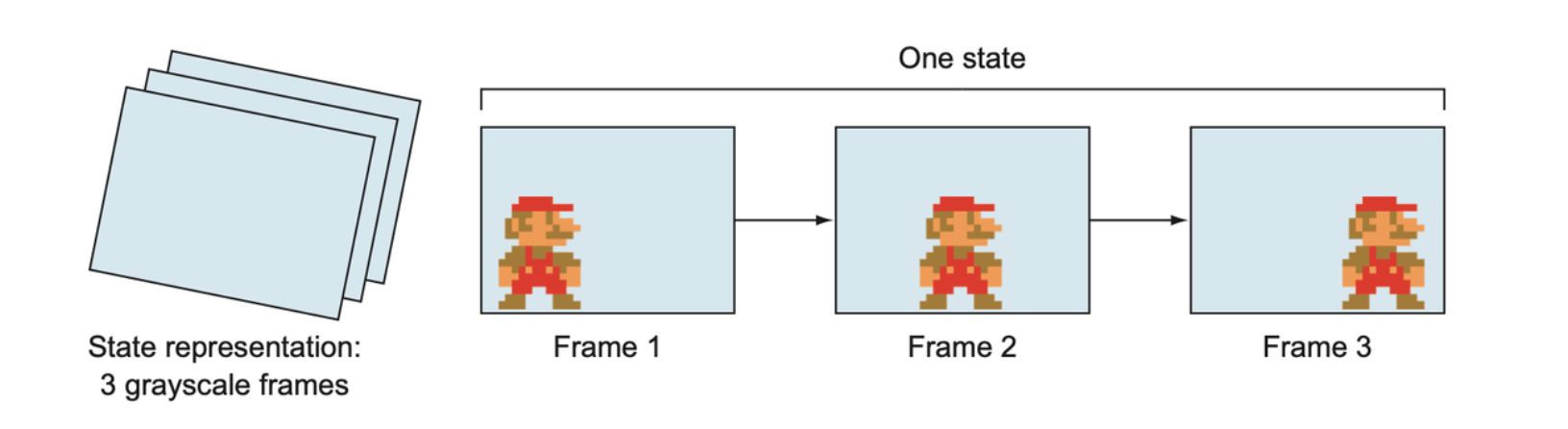
Each state given to the agent is a concatenation of the three most recent (grayscale) frames in the game. This is necessary so that the model can have access to not just the position of objects, but also their direction of movement.
We need three functions to handle the states:
prepare_state(state): Downscale state and converts to grayscale, converts to a pytorch tensor and adds a batch dimension.prepare_multi_state(state1, state2): Given an existing 3-frame state1 and a new single frame2, adds the latest frame to the queue.prepare_initial_state(state, N=3): Creates a state with three copies of the same frame and adds a batch dimension.
Setting up the Q-network and policy function
DQN is used for our agent here. It is consisted with four layers of
convolution networks. The activation function used here is
ELU. DQN needs a policy function, which selects action from
the Q values return by DQN.
Policy function
We will use a policy that begins with a softmax policy to encourage exploration, and after a fixed number of game steps we will switch to an epsilon-greedy strategy.
def policy(qvalues, eps=None): |
If eps is not provided, we sample from the softmax of Q
values.
Experience replay
An experience replay class contains a list of experiences, each of which is a tuple of \((S_t, a_t, r_t, S_{t+1})\).
from random import shuffle |
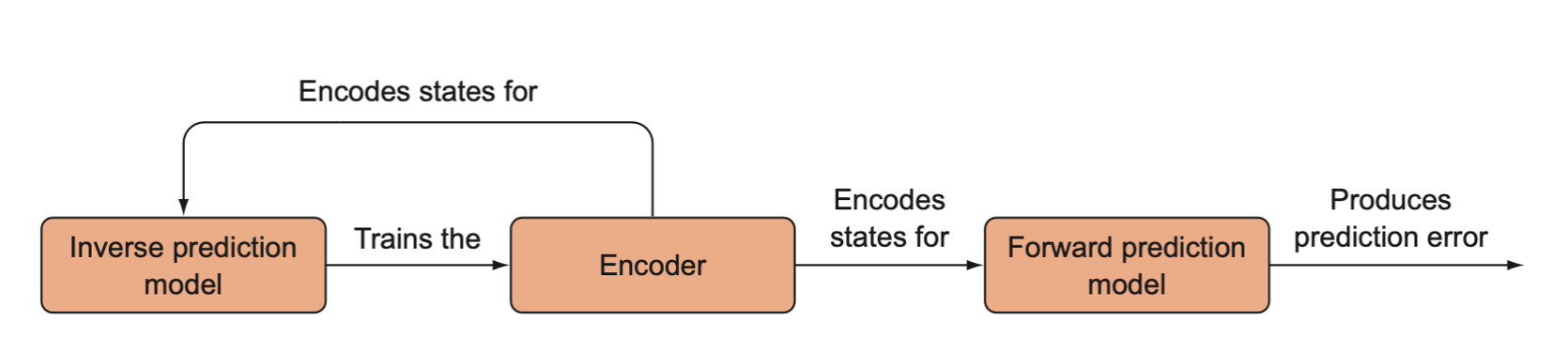
Intrinsic curiosity module
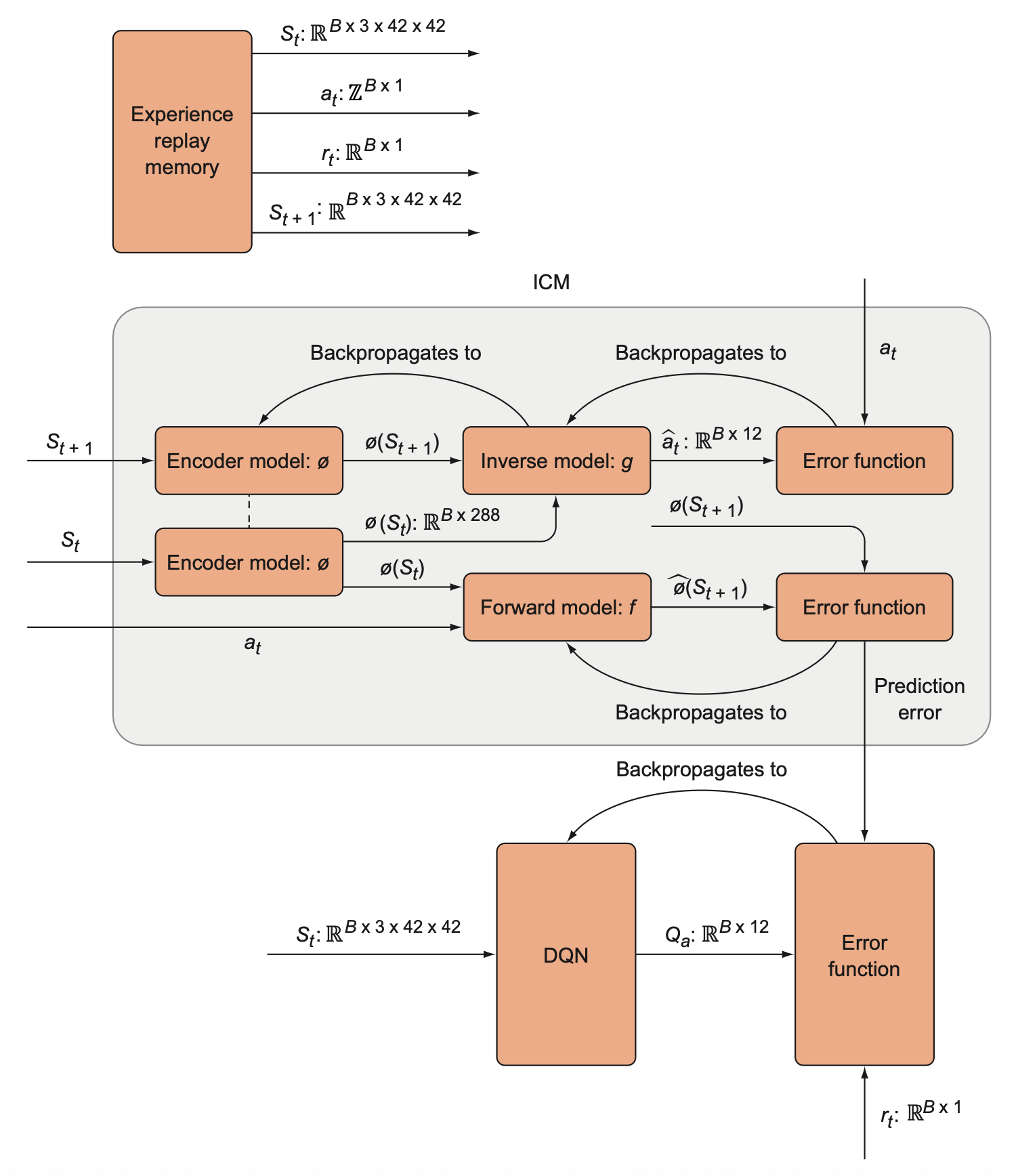
A high-level overview of the intrinsic curiosity module (ICM). The ICM has three components that are each separate neural networks. The encoder model encodes states into a low-dimensional vector, and it is trained indirectly through the inverse model, which tries to predict the action that was taken given two consecutive states. The forward model predicts the next encoded state, and its error is the prediction error that is used as the intrinsic reward.
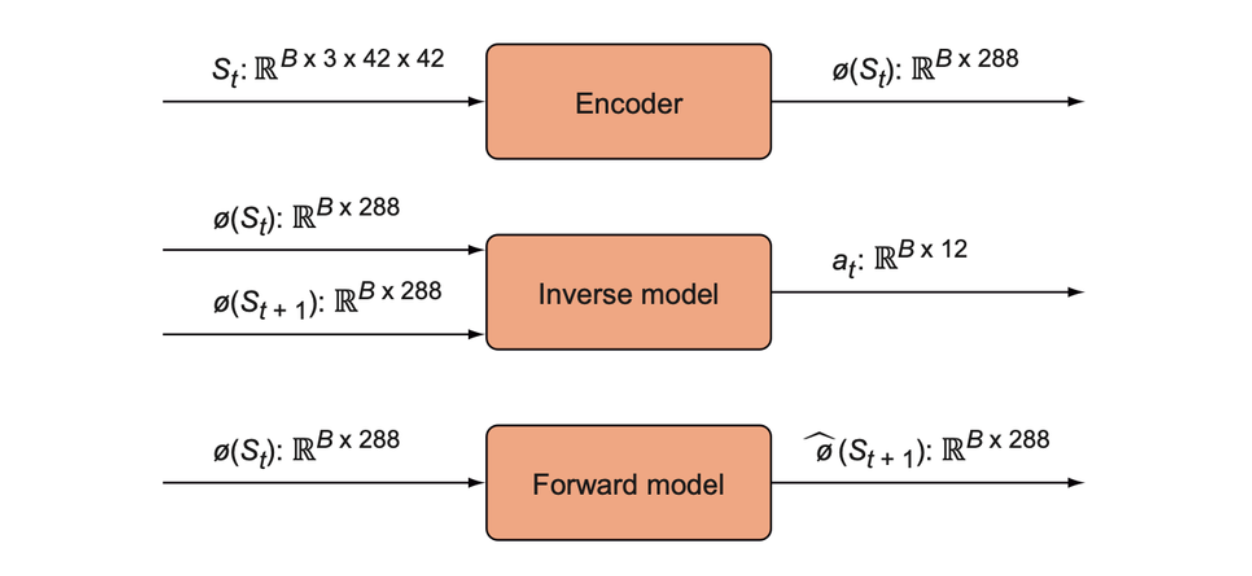
Below shows the type and dimensionality of the inputs and outputs of each component of the ICM.
The DQN and the ICM contribute to a single overall loss function that is given to the optimizer to minimize with respect to the DQN and ICM parameters. The DQN’s Q value predictions are compared to the observed rewards. The observed rewards, however, are summed together with the ICM’s prediction error to get a new reward value.
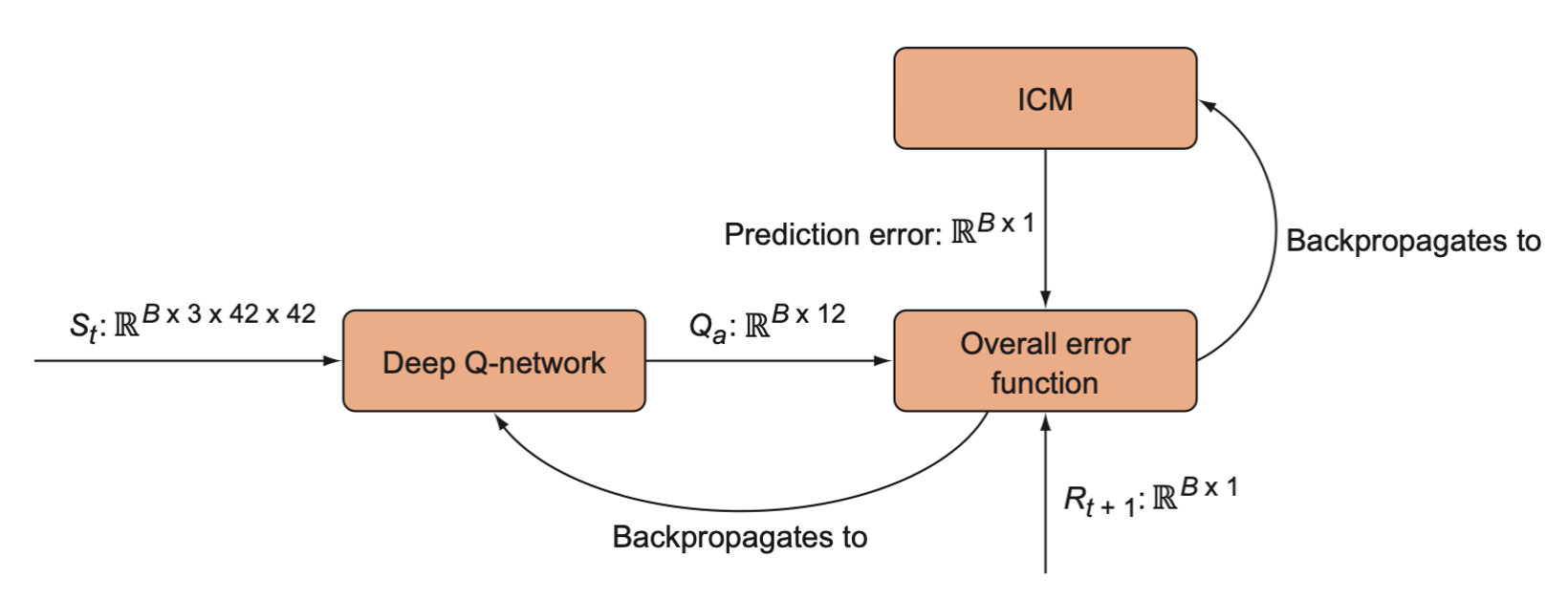
A complete view of the overall algorithm, including the ICM. First we generate \(B\) samples from the experience replay memory and use these for the ICM and DQN. We run the ICM forward to generate a prediction error, which is then provided to the DQN’s error function. The DQN learns to predict action values that reflect not only extrinsic (environment provided) rewards but also an intrinsic (prediction error-based) reward.
- The forward model is a simple two-layer neural network with linear layers.
- The inverse model is also a simple two-layer neural network with linear layers.
- The encoder is a neural network composed of four convolutional layers (with an identical architecture to the DQN)
The overall loss function defined by all four models is
\[ \text{minimize} [\lambda \cdot Q_\text{loss} + (1 - \beta)F_\text{loss} + \beta \cdot G_\text{loss}] \]
ICM
def ICM(state1, action, state2, forward_scale=1., inverse_scale=1e4): |
Mini-batch train
def minibatch_train(use_extrinsic=True): |
Main training loop
The final training process is defined as follows:
from IPython.display import clear_output |