Introduction
Reinforcement learning
Reinforcement learning is a generic framework for representing and solving control tasks, but within this framework we are free to choose which algorithm we want to apply to a particular control task.
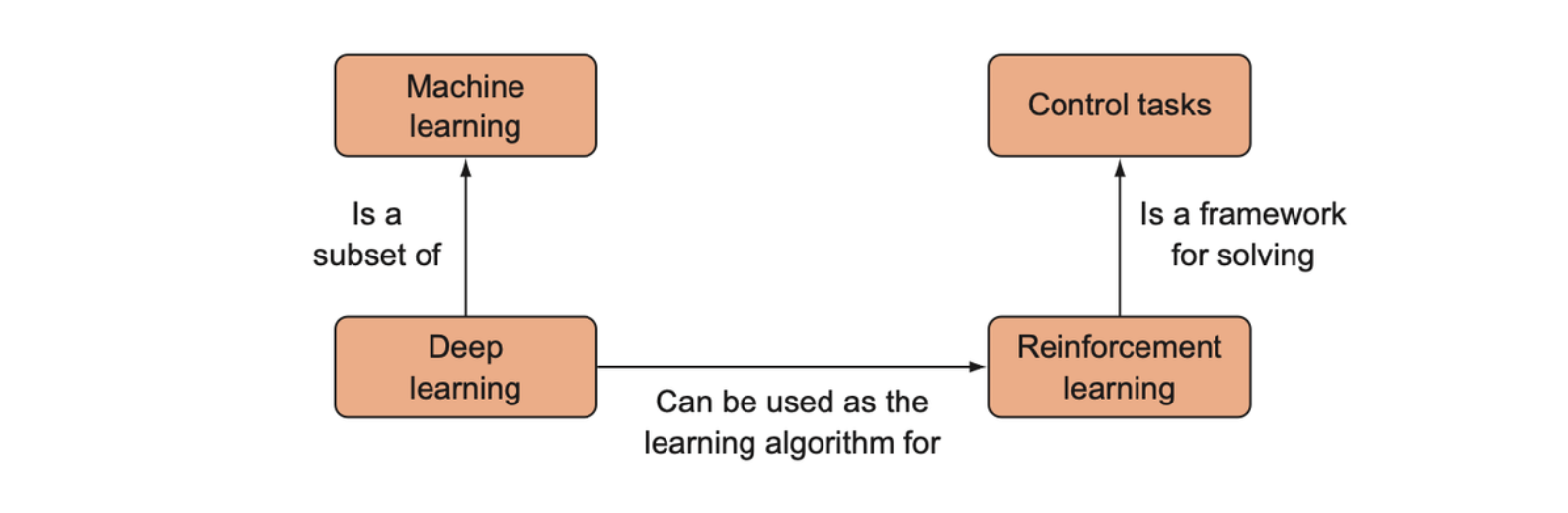
In control tasks, we similarly have a space of data to process, but each piece of data also has a time dimension —— the data exists in both time and space. This means that what the algorithm decides at one time is influenced by what happened at a previous time. Time makes the training task dynamic —— the data set upon which the algorithm is training is not necessarily fixed but changes based on the decisions the algorithm makes.
The algorithm of reinforcement learning has a single objective —— maximizing its reward —— and in order to do this it must learn more elementary skills to achieve the main objective. This is why it is called reinforcement learning: we either positively or negatively reinforce certain behaviors using reward signals.
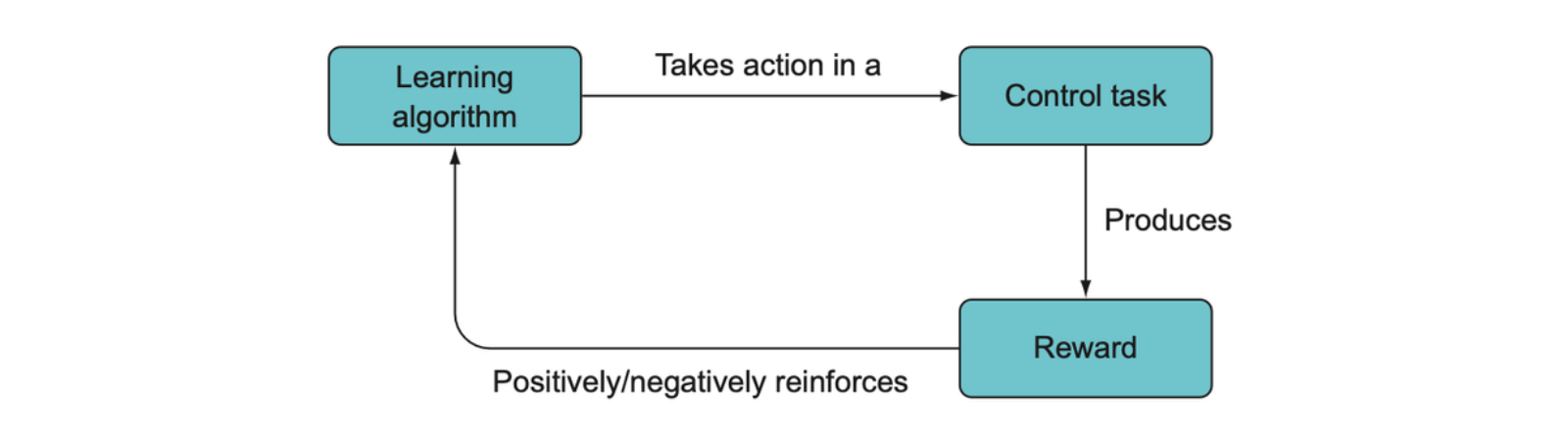
In the RL framework, some kind of learning algorithm decides which actions to take for a control task (e.g., driving a robot vacuum), and the action results in a positive or negative reward, which will positively or negatively reinforce that action and hence train the learning algorithm.
Dynamic programming versus Monte Carlo
Dynamic programming solves a problem by decomposing them into smaller and smaller subproblems until it gets to a simple subproblem that can be solved without further information.
In RL, we can’t apply dynamic programming exactly since we often have nuanced situations that may include some element of randomness.
A Monte Carlo method is essentially a random sampling from the environment. In many real-world problems, we have at least some knowledge of how the environment works, so we end up employing a mixed strategy of some amount of trial and error and some amount of exploiting what we already know about the environment to directly solve the easy sub-objectives.
The reinforcement learning framework
Richard Bellman introduced dynamic programming as a general method of solving certain kinds of control or decision problems, but it occupies an extreme end of the RL continuum. Bellman’s more important contribution was helping develop the standard framework for RL problems, this forces us to formulate our problems in a way that is amenable to dynamic programming-like problem decomposition, such that we can iteratively optimize over local sub-problems and make progress toward achieving the global high-level objective.
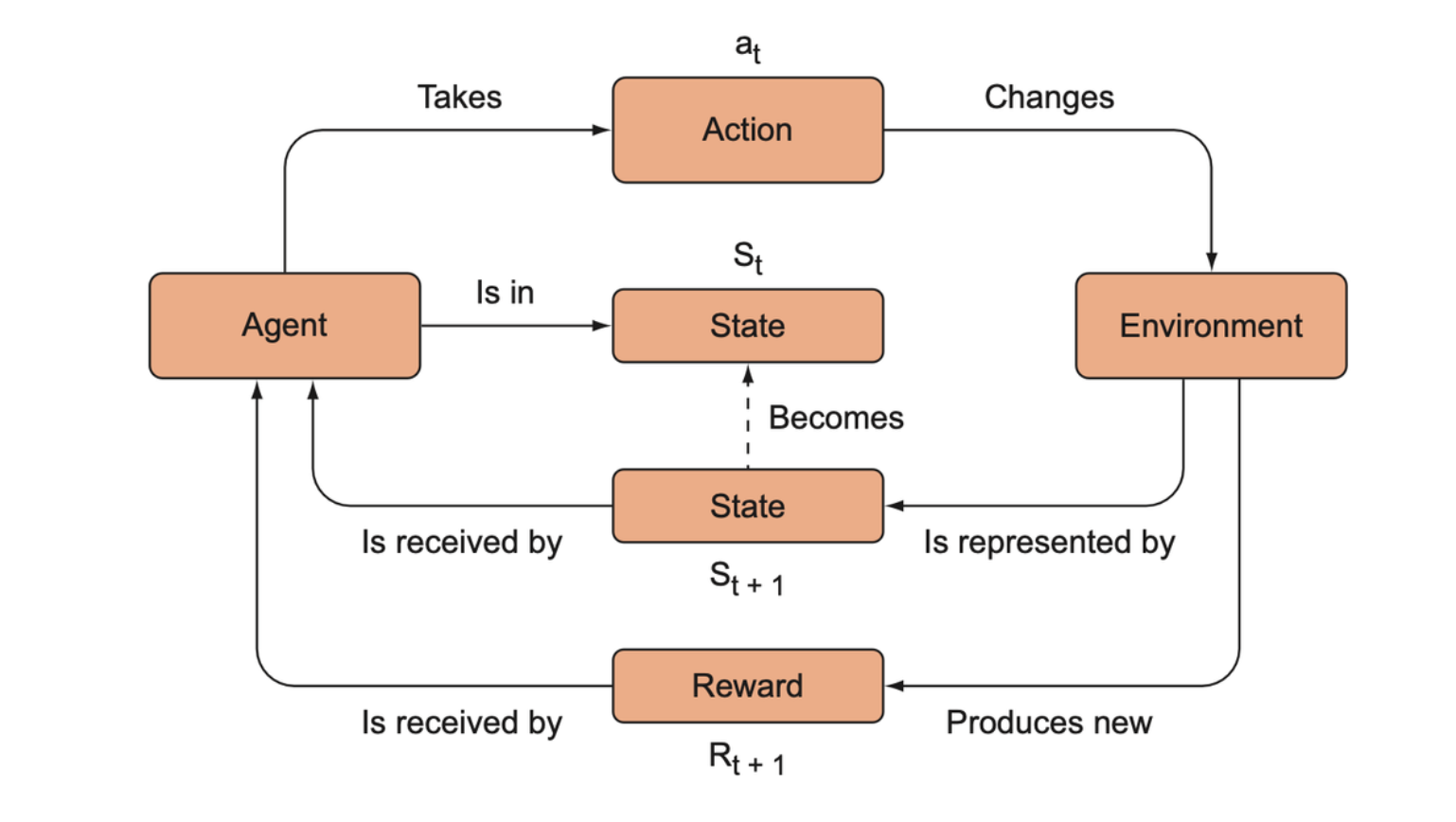
The standard framework for RL algorithms. The agent takes an action in the environment, such as moving a chess piece, which then updates the state of the environment. For every action it takes, it receives a reward (e.g., +1 for winning the game, –1 for losing the game, 0 otherwise). The RL algorithm repeats this process with the objective of maximizing rewards in the long term, and it eventually learns how the environment works.
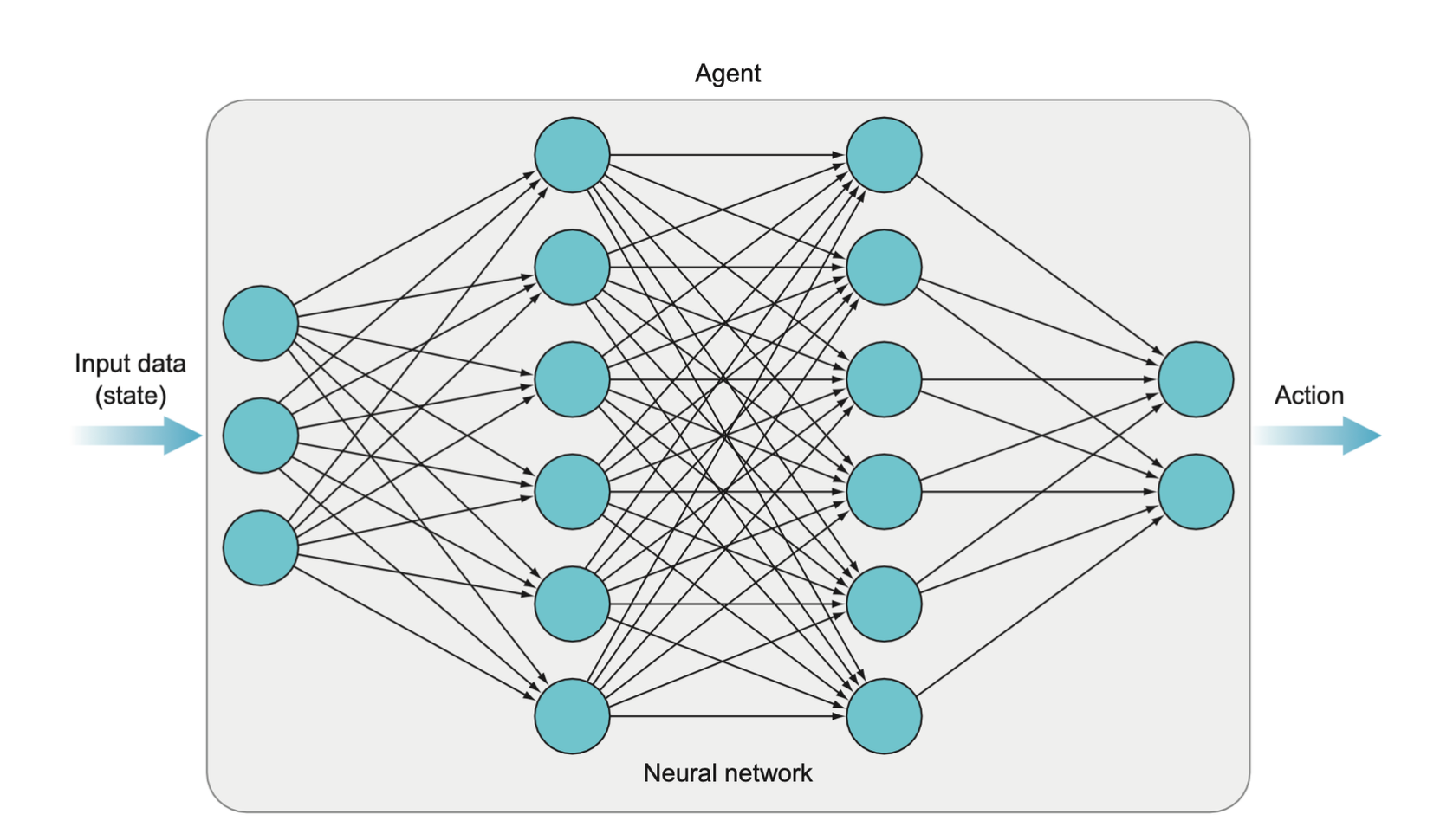
The input data (which is the state of the environment at some point in time) is fed into the agent (implemented as a deep neural network in this book), which then evaluates that data in order to take an action. The process is a little more involved than shown here, but this captures the essence.