Toward artificial general intelligence
Toward artificial general intelligence
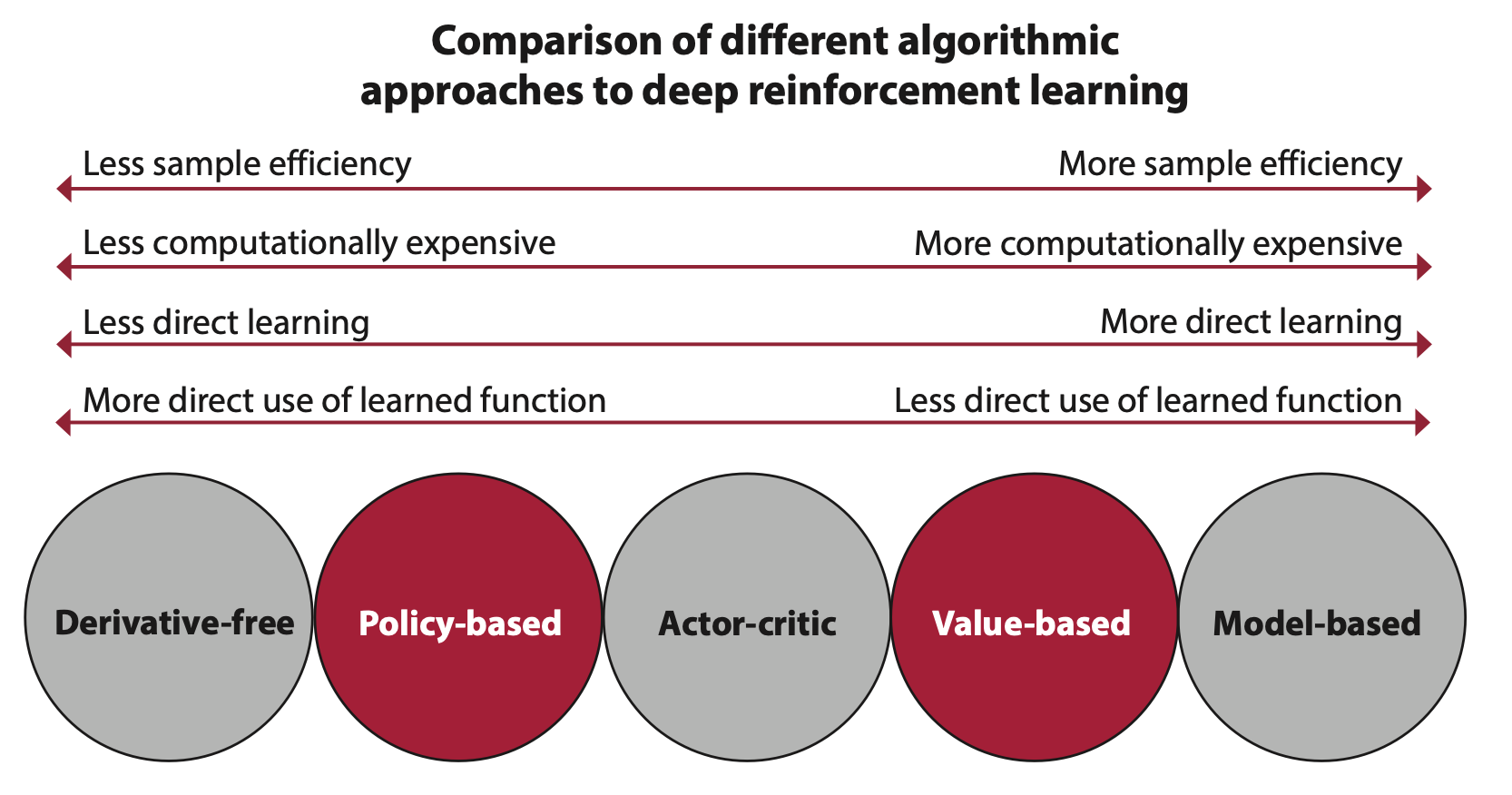
Concepts
Markov decision processes
Think about a problem, and break it down into states, observations, actions and all the components that would make that problem an MDP.
Planning methods
Value iteration and policy iteration are methods that help find optimal policies of problems that have MDPs available. Policies are nothing but universal plans —— a plan for every situation.
Bandit methods
When MDP is not available, the challenge becomes to find the optimal action or action distribution in the fewest number of episodes, that is, minimizing total regret.
Tabular reinforcement learning
Sequential decision-making problems under uncertainty are at the core of reinforcement learning when presented in a way that can be more easily studied.
Algorithms include first-visit and every-visit Monte Carlo prediction, temporal-difference prediction, n-step TD, and TD(\(\lambda\)).
And more control methods are covered such as first-visit and every visit Monte Carlo control, SARSA, Q-learning, double Q-learning. And more advanced methods, such as SARSA(\(\lambda\)) and Q(\(\lambda\)).
And some model based methods such as Dyna-Q and trajectory sampling.
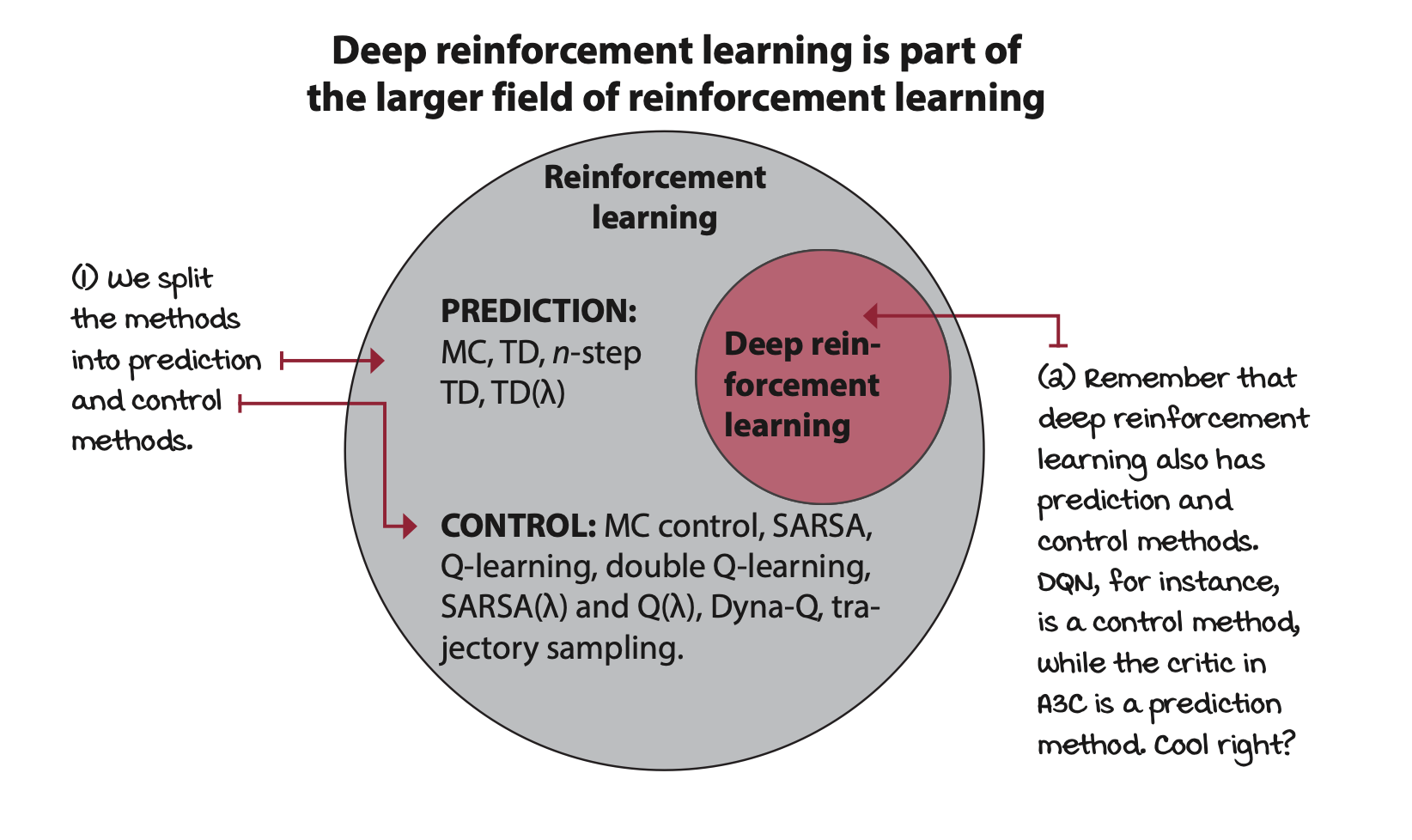
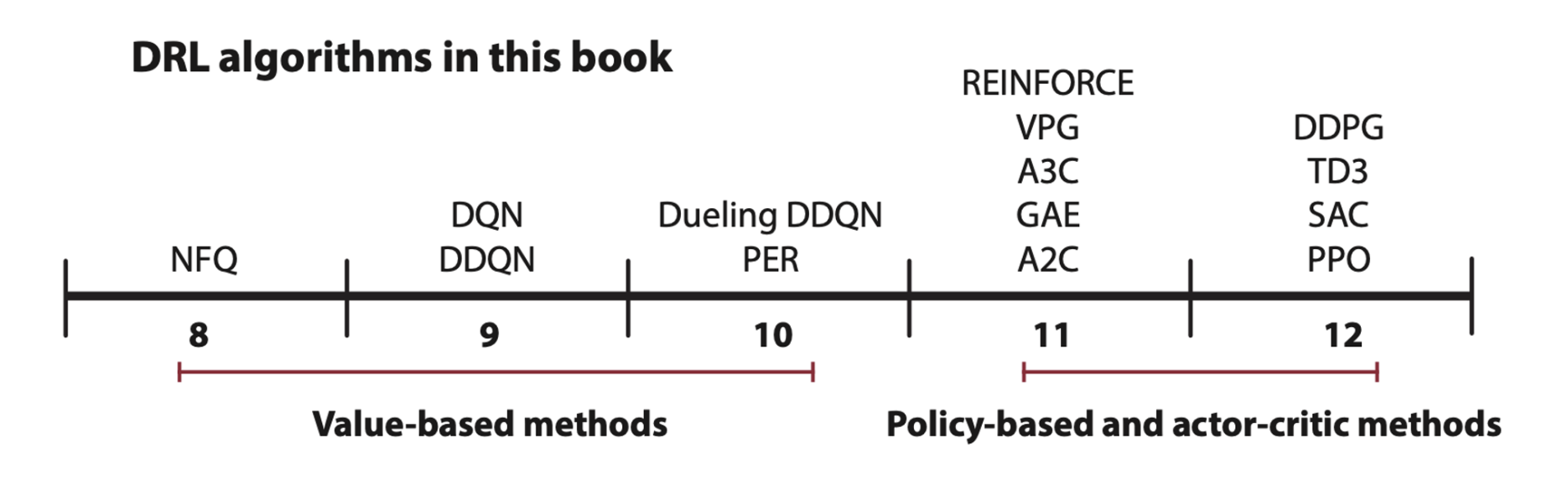
Value-based deep reinforcement learning
Neural fitted Q-iteration (NFQ), deep Q-networks (DQN), double deep Q-networks (DDQN), dueling architecture in DDQN (dueling DDQN), and prioritized experience replay (PER).
Policy-based and actor-critic deep reinforcement learning
Model-based deep reinforcement learning
Model-based deep reinforcement learning is the use of deep learning techniques for learning the transition, the reward function, or both, and then using that for decision making. Model-based methods are the most sample efficient in reinforcement learning.
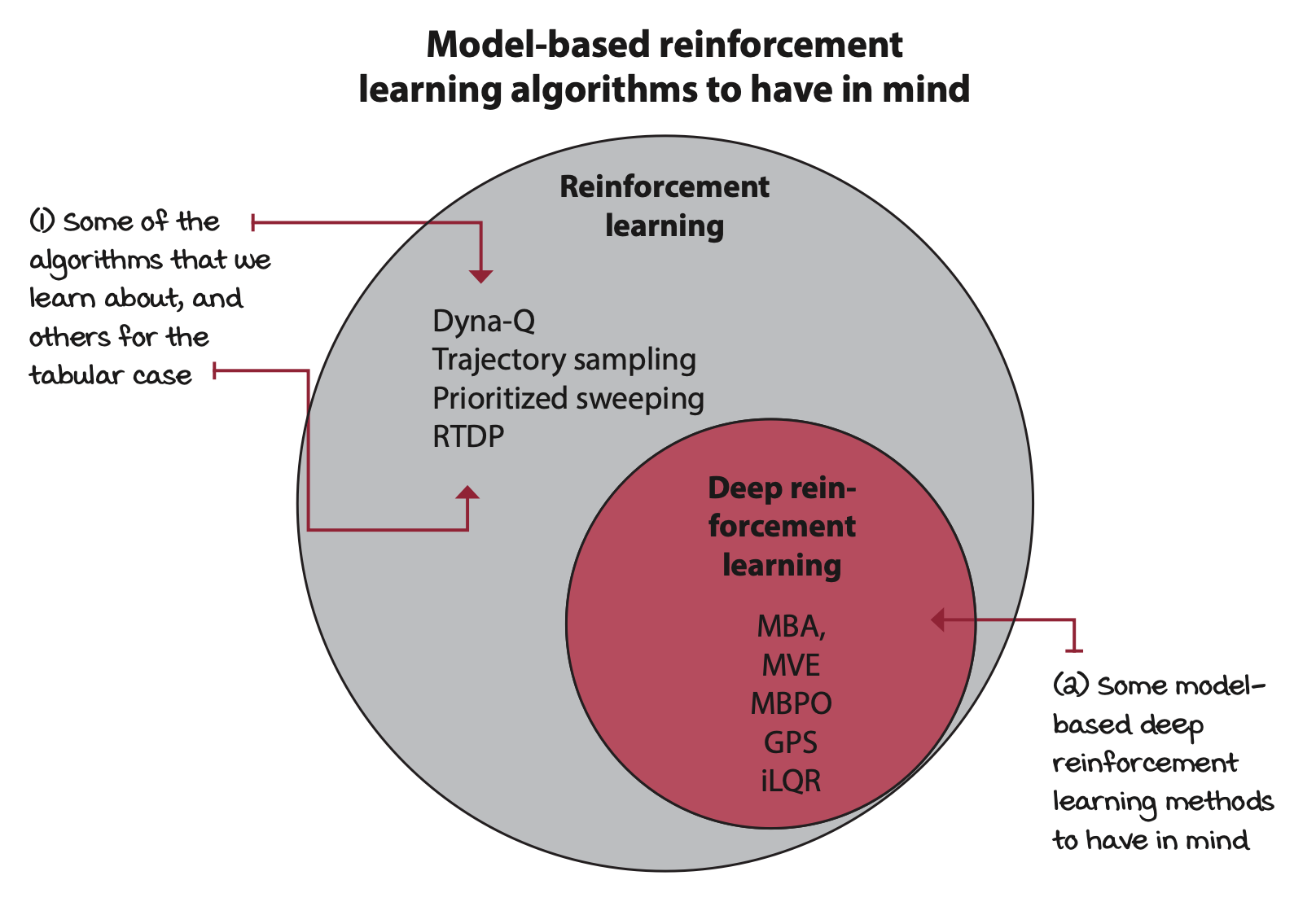
But learning a model of the dynamics of an environment, in addition to a policy, a value function, or both, is more computationally expensive. And if you were to learn only a model of the dynamics, then the compounding of model error from the model would make your algorithm impractical.
Derivative-free optimization methods
Genetic algorithms and evolution strategies. Derivative-free methods, which are also known as gradient-free, black-box, and zeroth-order methods, don’t require derivatives and can be useful in situations in which gradient-based optimization methods suffer.
More advanced concepts toward AGI
General intelligence is the ability to combine various cognitive abilities to solve new problems.
- Advanced exploration strategies
- Inverse reinforcement learning
- Transfer learning
- Multi-task learning
- Curriculum learning
- Meta learning
- Hierarchical reinforcement learning
- Multi-agent reinforcement learning
- Explainable AI, safety, fairness, and ethical standards