Achieving goals more effectively and efficiently
Efficiency is doing things right; effectiveness is doing the right things.
Two improvements will be made to the agents.
- Use the \(\lambda\)-return for the policy evaluation requirements of the generalized policy iteration pattern.
- Explore algorithms that use experience samples to learn a model of the environment, a Markov decision process (MDP). The group of algorithms that attempt to learn a model of the environment is referred to as model-based reinforcement learning.
Learning to improve policies using robust targets
SARSA(λ): Improving policies after each step based on multi-step estimates
SARSA(\(\lambda\)) is a straightforward improvement to the original SARSA agent. The main difference between SARSA and SARSA(\(\lambda\)) is that we use \(\lambda\)-return in SARSA(\(\lambda\)).
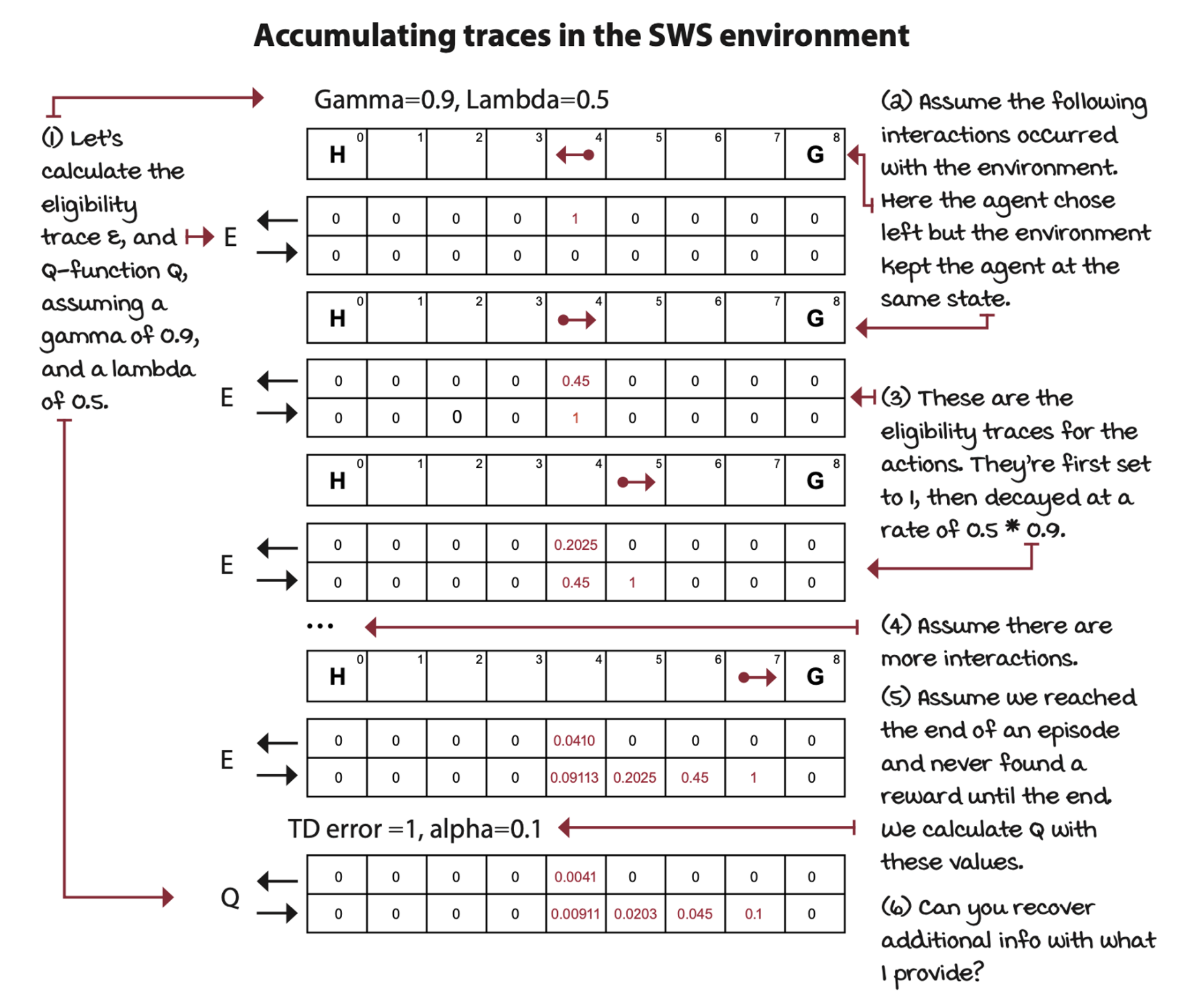
The accumulating trace combines a frequency and a recency heuristic. Traces have a way for combining frequency (how often you try a state-action pair) and recency (how long ago you tried a state-action pair) heuristics implicitly encoded in the trace mechanism.

Watkin’s Q(λ): Decoupling behavior from learning, again
\(Q(\lambda)\) is an extension of Q-learning that uses the \(\lambda\)-return for policy-evaluation requirements of the generalized policy-iteration pattern. The only change we’re doing here is replacing the TD target for off-policy control (the one that uses the max over the action in the next state) with a \(\lambda\)-return for off-policy control.
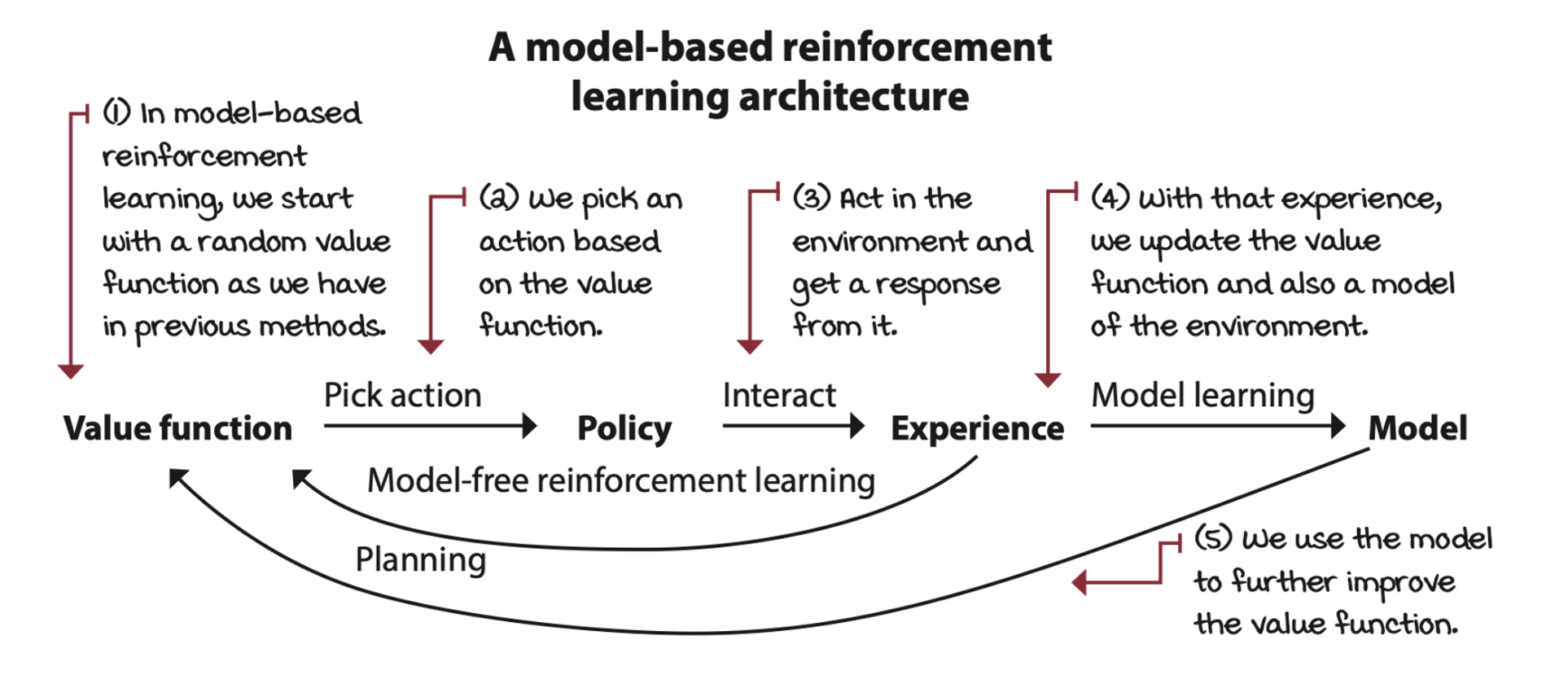
Agents that interact, learn, and plan
The advantage of model-free RL over planning methods is that the former doesn’t require MDPs. SARSA, Q-learning algorithms are model-based reinforcement learning methods, which don’t need a MDP in advance, but can learn through interacting with environment.
Dyna-Q: Learning sample models
One of the most well-known architectures for unifying planning and model-free methods is called Dyna-Q. Dyna-Q consists of interleaving a model-free RL method, such as Q-learning, and a planning method, similar to value iteration, using both experiences sampled from the environment and experiences sampled from the learned model to improve the action-value function.
Trajectory sampling: Making plans for the immediate future
While Dyna-Q samples the learned MDP uniformly at random, trajectory sampling gathers trajectories, that is, transitions and rewards that can be encountered in the immediate future.
The traditional trajectory-sampling approach is to sample from an initial state until reaching a terminal state using the on-policy trajectory. But nothing is limited. Samples starting from the current state can also be a choice. As long as it is sampling a trajectory, it is called trajectory sampling.