Introduction
Deep reinforcement learning
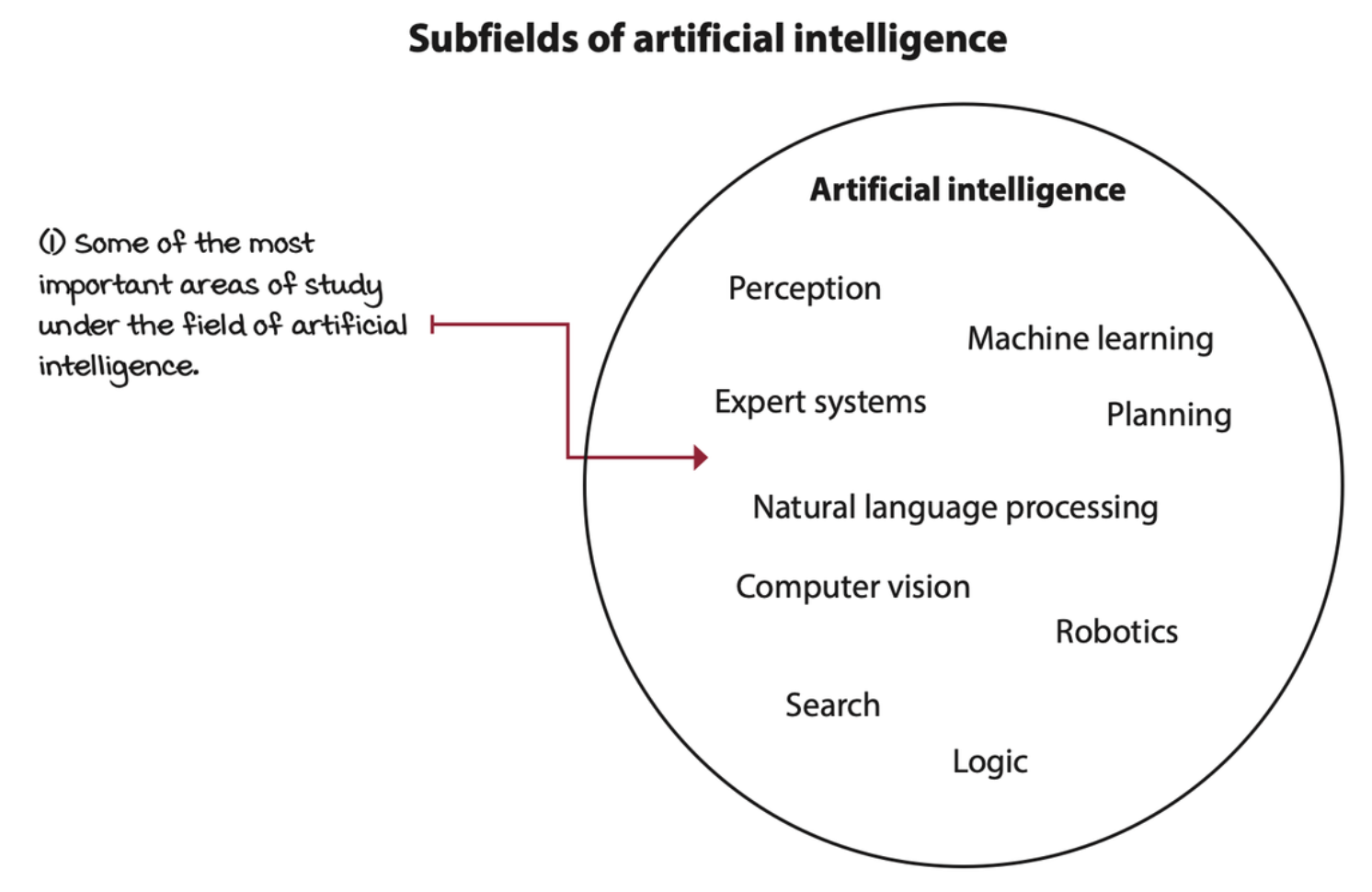
Deep reinforcement learning (DRL) is a machine learning approach to artificial intelligence concerned with creating computer programs that can solve problems requiring intelligence. The distinct property of DRL programs is learning through trial and error from feedback that’s simultaneously sequential, evaluative, and sampled by leveraging powerful non-linear function approximation.
Deep reinforcement learning is a machine learning approach to artificial intelligence
There are three main branches of ML: supervised, unsupervised, and reinforcement learning.
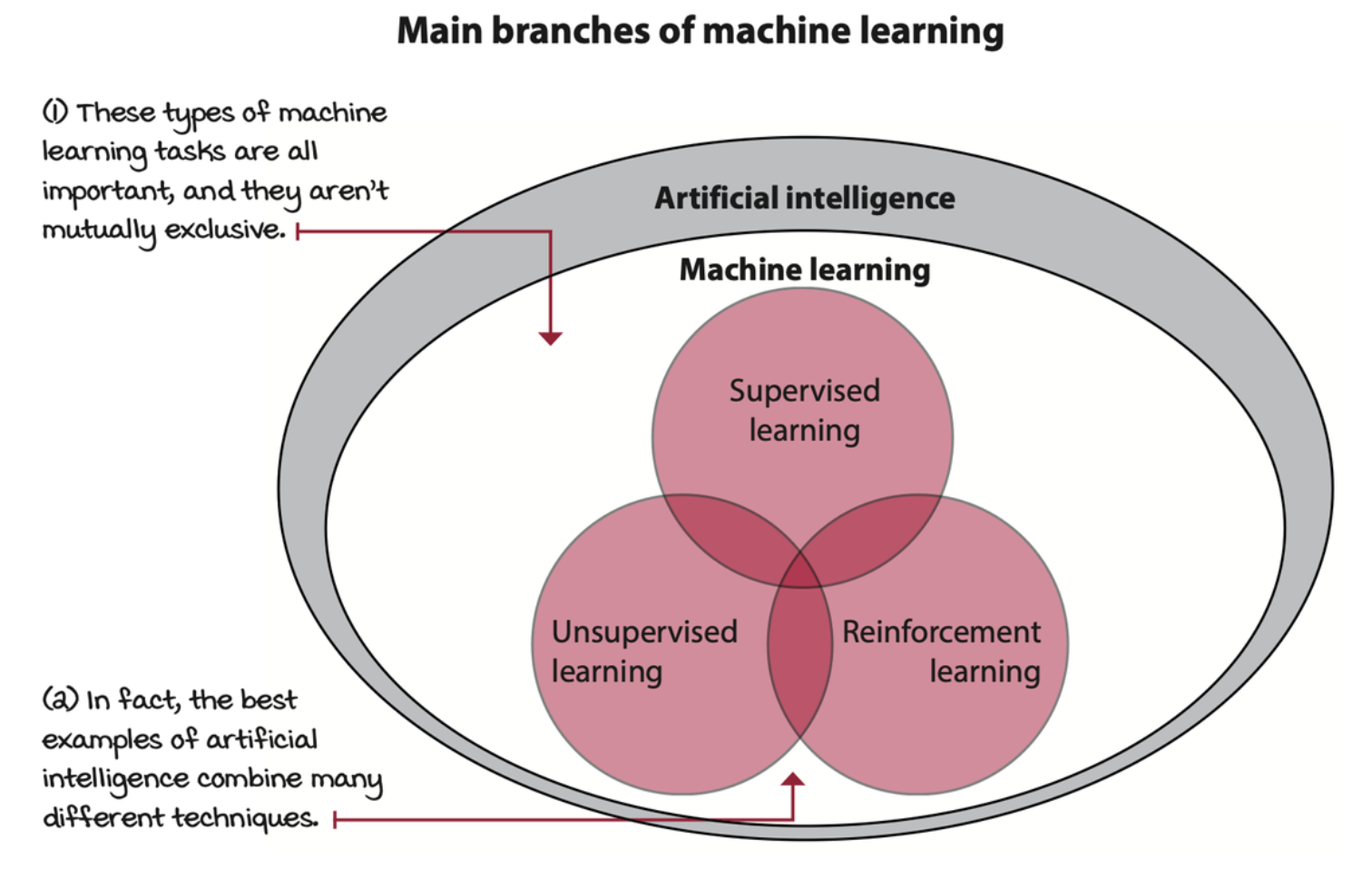
- Supervised learning (SL): is the task of learning from labeled data.
- Unsupervised learning (UL): is the task of learning from unlabeled data.
- Reinforcement learning (RL): is the task of learning through trial and error.
Deep learning (DL) is a collection of techniques and methods for using neural networks to solve ML tasks, whether SL, UL, or RL. DRL is simply the use of DL to solve RL tasks.
Deep reinforcement learning is concerned with creating computer programs
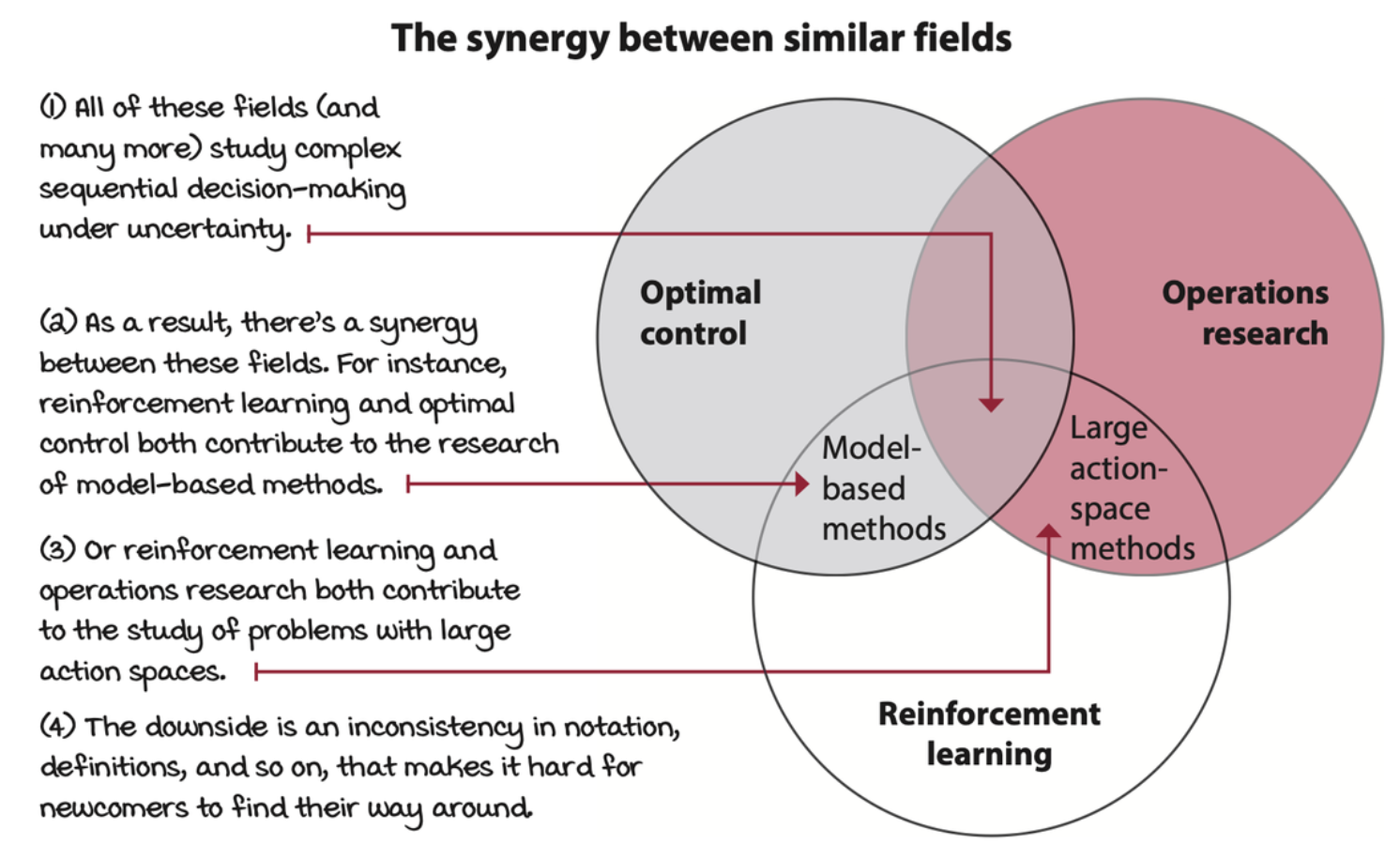
DRL is about complex sequential decision-making problems under uncertainty.
In DRL, the computer programs that solve complex decision-making problems under uncertainty are called agents.
Deep reinforcement learning agents can solve problems that require intelligence
On the other side of the agent is the environment. The strict boundary between the agent and the environment is that: the agent can only have a single role: making decisions. Everything that comes after the decision gets bundled into the environment.
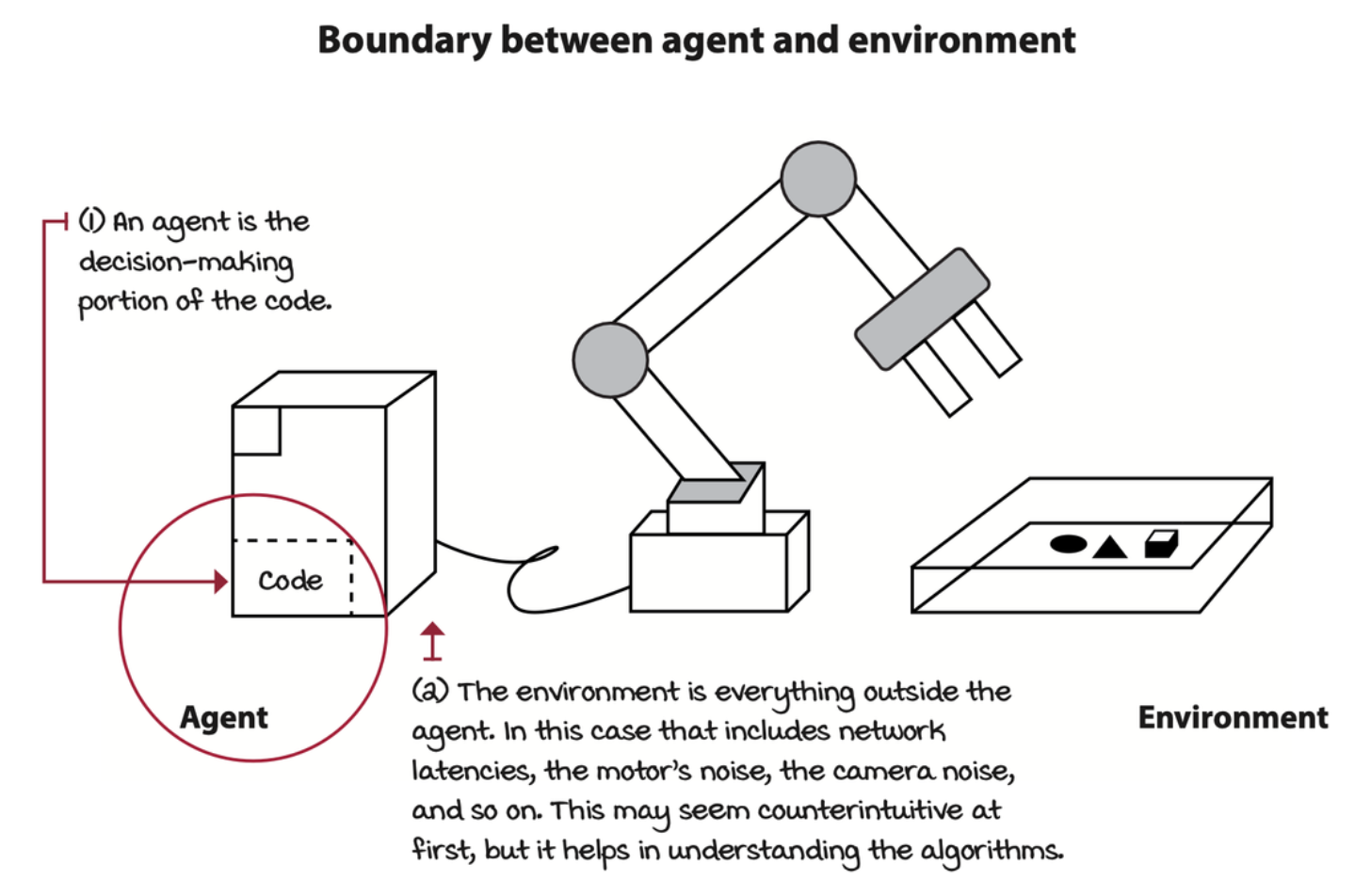
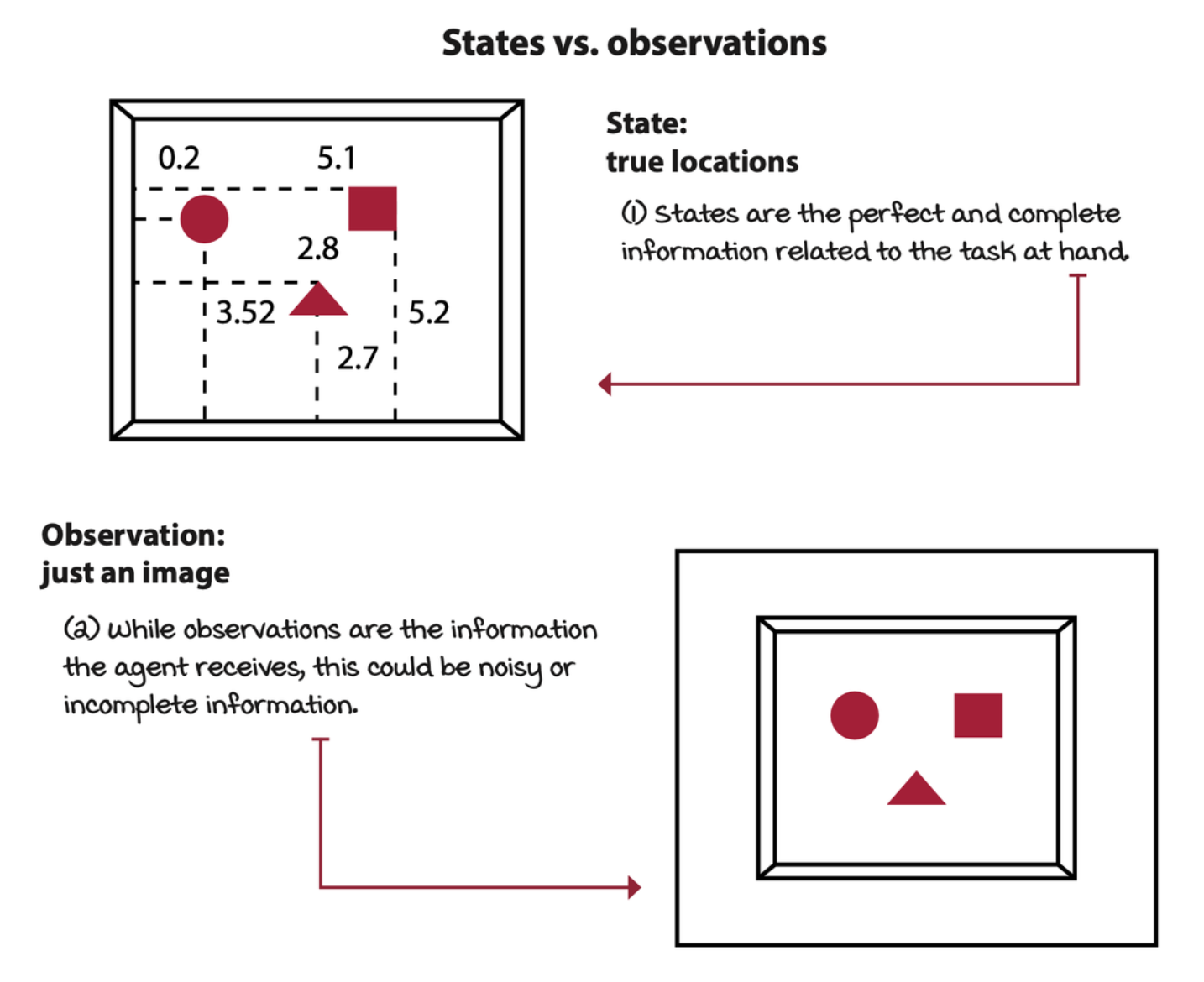
The environment is represented by a set of variables related to the problem. This set of variables and all the possible values that they can take are referred to as the state space. A state is an instantiation of the state space, a set of values the variables take. Often, agents don’t have access to the actual full state of the environment. The part of a state that the agent can observe is called an observation.
At each state, the environment makes available a set of actions the agent can choose from. The agent influences the environment through these actions. The environment may change states as a response to the agent’s action. The function that’s responsible for this mapping is called the transition function. The environment may also provide a reward signal as a response. The function responsible for this mapping is called the reward function. The set of transition and reward functions is referred to as the model of the environment.
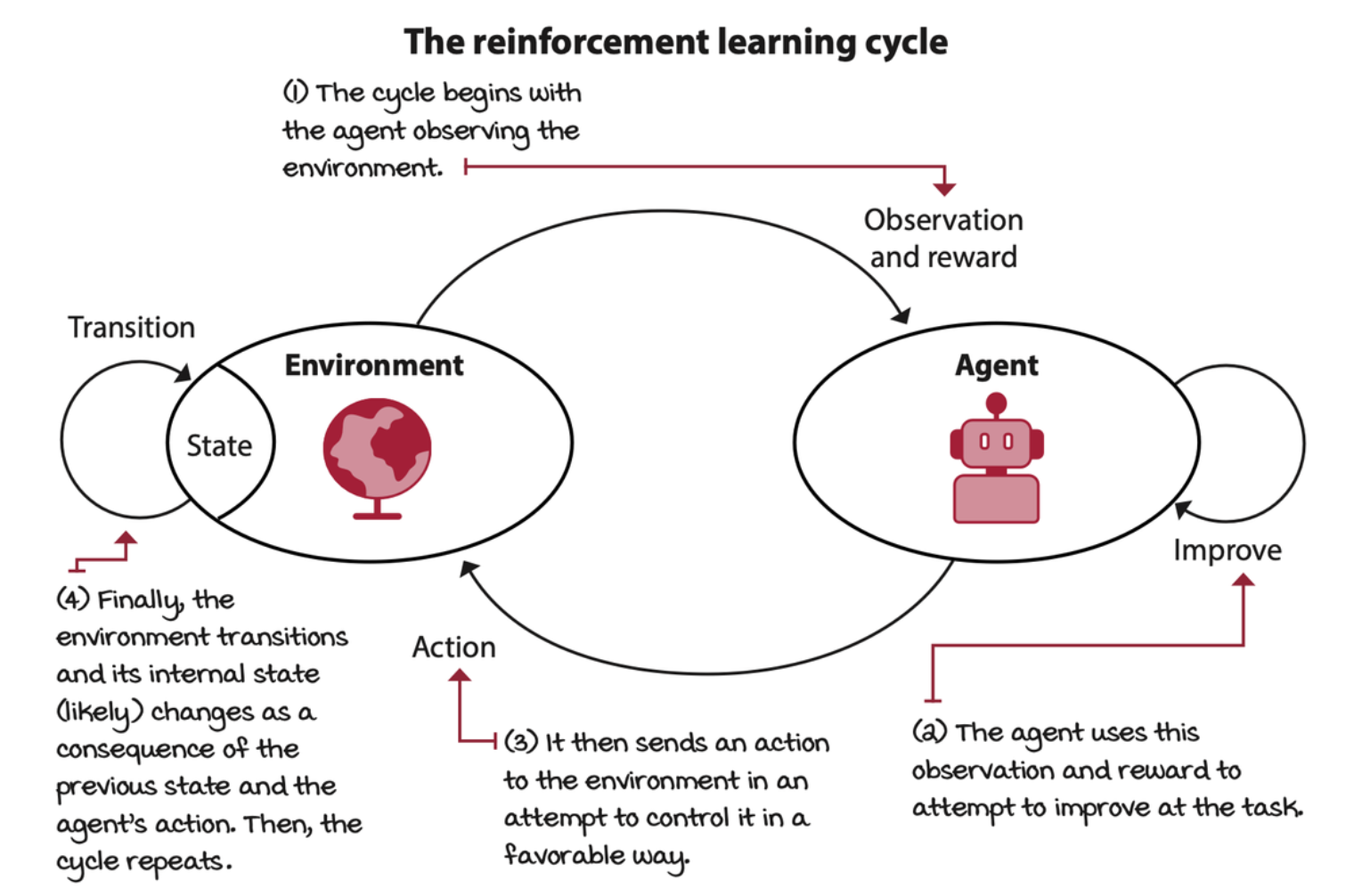
The agent has a three-step process:
- the agent interacts with the environment,
- the agent evaluates its behavior,
- and the agent improves its responses.
The agent can be designed to learn mappings from observations to actions called policies. The agent can be designed to learn the model of the environment on mappings called models. The agent can be designed to learn to estimate the reward-to-go on mappings called value functions.
Deep reinforcement learning agents improve their behavior
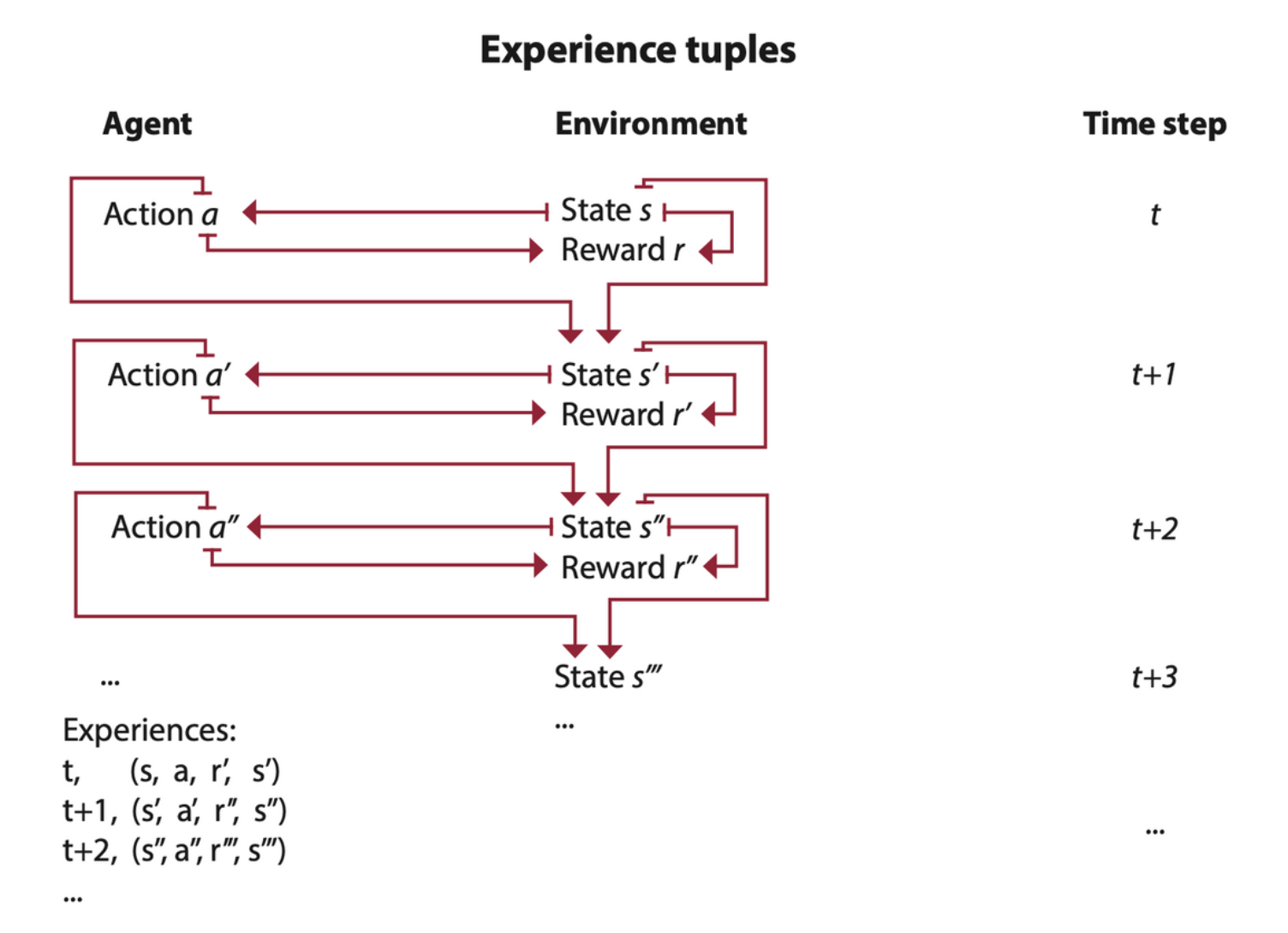
The interactions between the agent and the environment go on for several cycles. Each cycle is called a time step. At each time step, the agent observes the environment, takes action, and receives a new observation and reward. The set of the state, the action, the reward, and the new state is called an experience. Every experience has an opportunity for learning and improving performance.
The task the agent is trying to solve may or may not have a natrual ending. Tasks that have a natrual ending, such as a game, are called episodic tasks. Conversely, tasks that don’t are called continuing tasks. The sequence of time steps from the beginning to the end of an episodic task is called an episode.
Deep reinforcement learning agents learn from sequential feedback
The action taken by the agent may have delayed consequences. The reward may be sparse and only manifest after several time steps. Thus the agent must be able to learn from sequential feedback. Sequential feedback gives rise to a problem referred to as the temporal credit assignment problem.
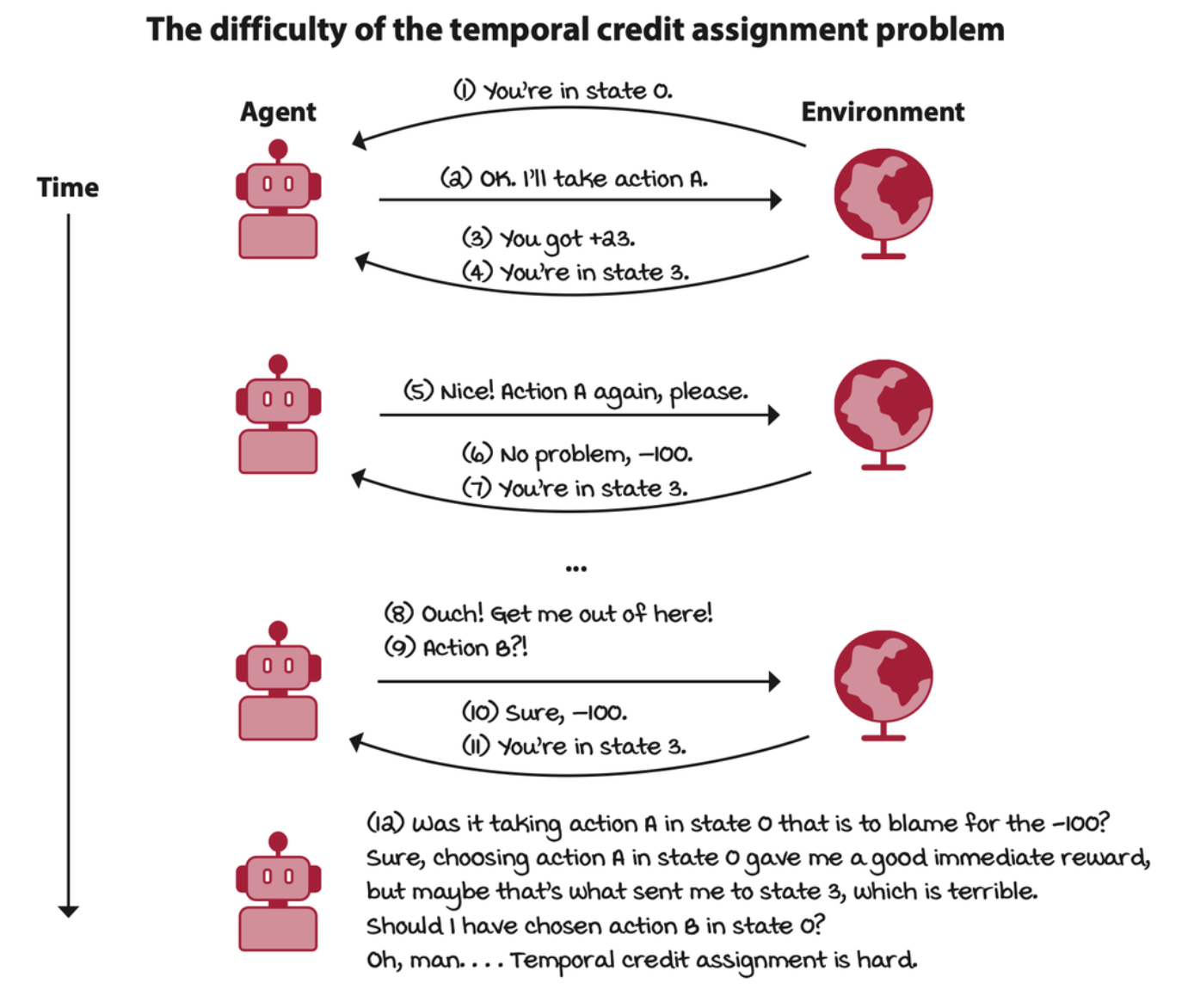
Deep reinforcement learning agents learn from evaluative feedback
The reward received by the agent may be weak. The agent must be able to learn from evaluative feedback. Evaluative feedback gives rise to the need for exploration. The agent must be able to balance the gathering of information with the exploitation of the current information.
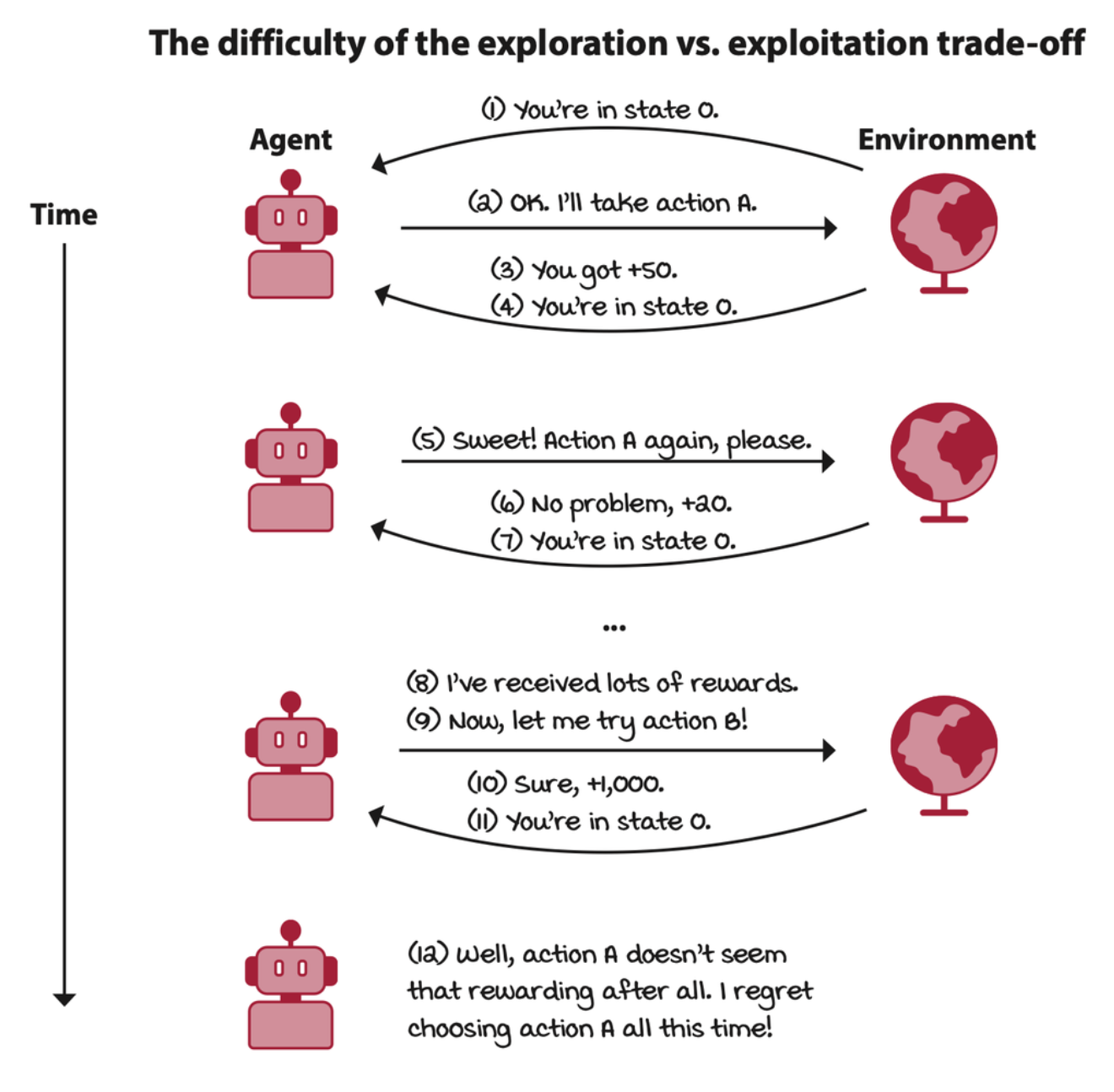
Deep reinforcement learning agents learn from sampled feedback
The reward received by the agent is merely a sample, and the agent doesn’t have access to the reward function. The agent must be able to learn from sampled feedback, and it must be able to generalize.
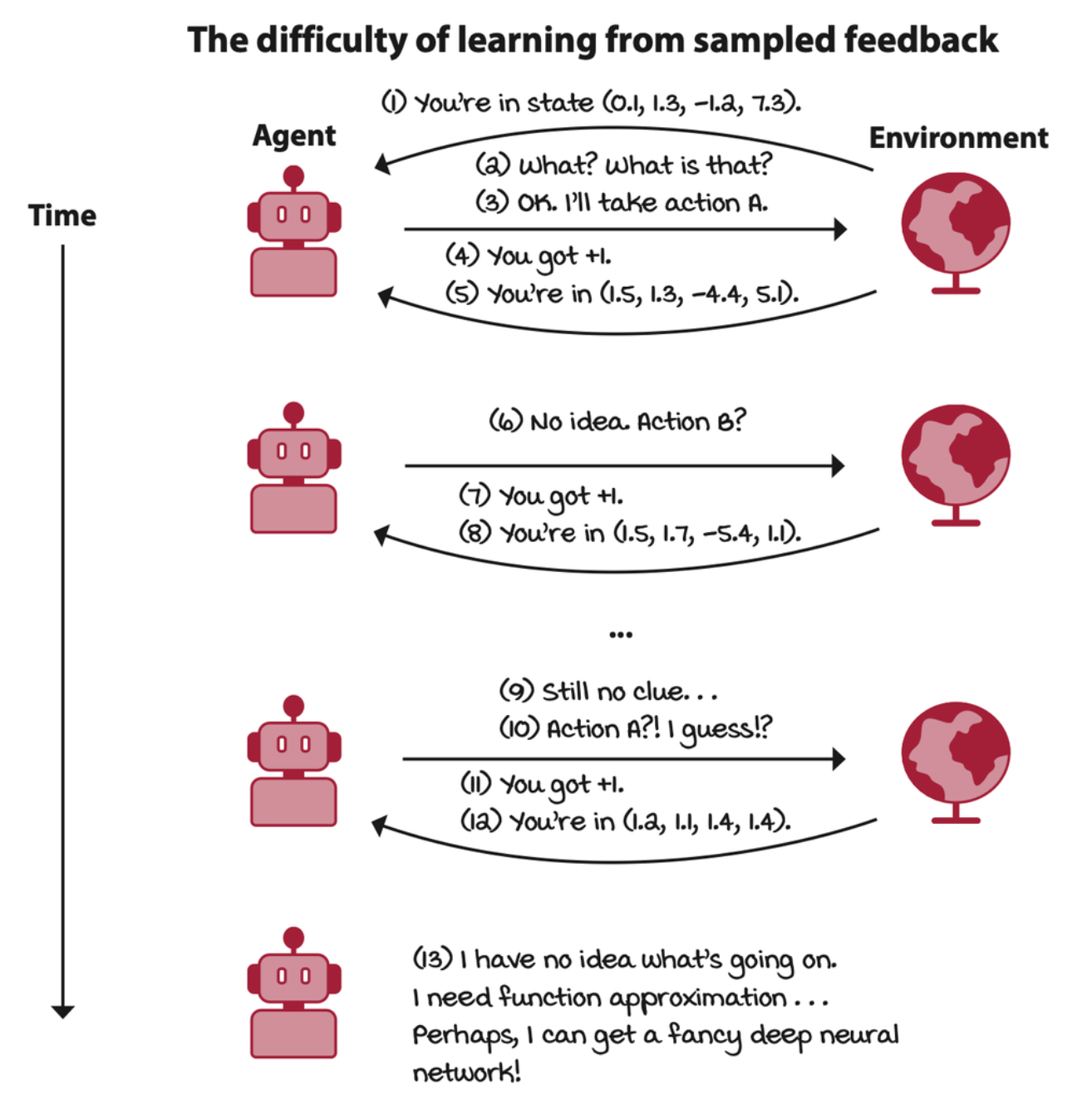
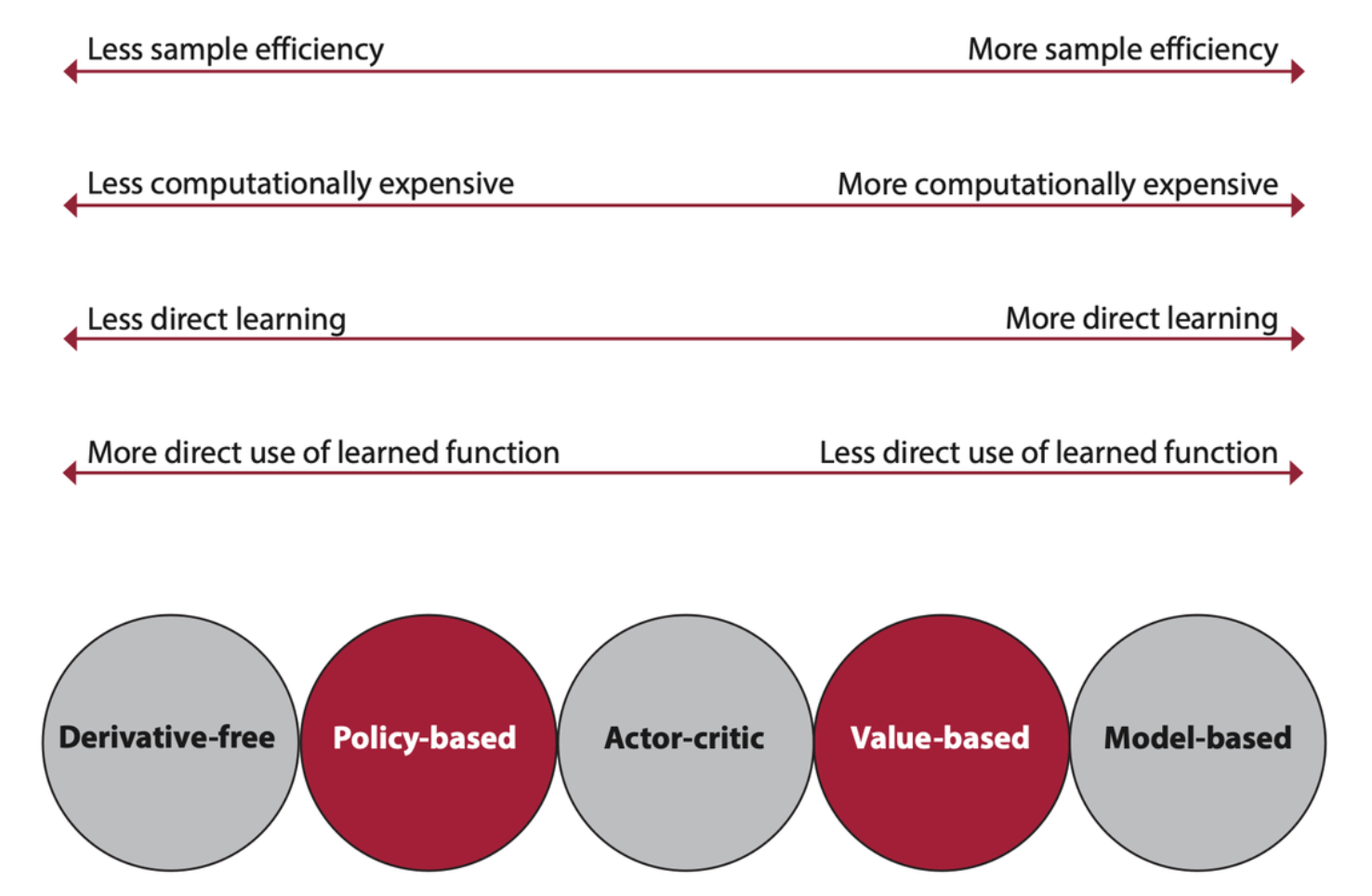
Agents that are designed to approximate policies are called policy-based; agents that are designed to approximate value functions are called value-based; agents that are designed to approximate models are called model-based; and agents that are designed to approximate both policies and value functions are called actor-critic. Agents can be designed to approximate one or more of these components.
The suitability of deep reinforcement learning
Strengths
RL is good at concrete, well specified tasks. Unlike SL (Supervised Learning), in which generalization is the goal.
Weaknesses
One of the most significant issues is that agents need millions of samples to learn well-performed policies. Another issue with DRL is with reward functions and understanding the meaning of rewards.
Comparison of different algorithmic approaches to deep reinforcement learning